As has become my practice, I celebrate the end of a year and the start of a new one here at AVC with back to back posts focusing on what happened and then thinking about what might happen.
Today, we focus on what happened in 2017.
Crypto:
I went back and looked at my predictions for 2017 and I completely whiffed on the breakout year for crypto. I did not even mention it in my post on New Year’s Day 2017.
Maybe I got tired of predicting a breakout year for crypto as I had mentioned it in my 2015 and 2016 predictions, but whatever the cause, I completely missed the biggest story of the year in tech.
If you look at the Carlota Perez technology surge cycle chart, which is a framework I like to use when thinking about new technologies, you will see that a frenzy develops when a new technology enters the material phase of the installation period. The frenzy funds the installation of the technology.
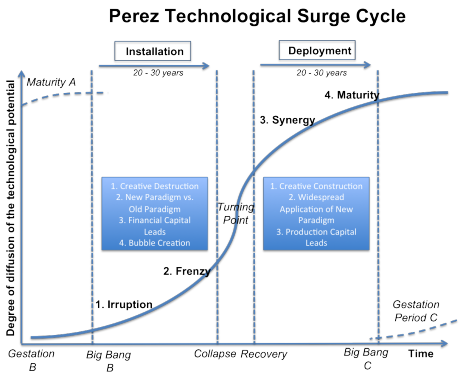
2017 is the year when crypto/blockchain entered the frenzy phase. Over $3.7bn was raised by various crypto teams/projects to build out the infrastructure of Internet 3.0 (the decentralized Internet). To put that number into context, that is about equal to the total seed/angel investment in the US in 2017. Clearly, not all of that money will be used well, maybe very little of it will be used well. But, like the late 90s frenzy in Internet 1.0 (the dialup Internet) provided the capital to build out the broadband infrastructure that was necessary for Internet 2.0 (the broadband/mobile Internet), the frenzy in the crypto/blockchain sector will provide the capital to build out the infrastructure for the decentralized Internet.
And we need that infrastructure badly. Transaction clearing times on public, open, scaled blockchains (BTC and ETH, for example) remind me of the 14.4 dialup period of the Internet. You can get a taste of what things will be like, but you can’t really use the technology yet. It just doesn’t work at scale. But it will and the money that is getting invested via the frenzy we are in is going to make that happen.
This is the biggest story in tech in 2017 because transitions from Internet 1.0 to Internet 2.0 to Internet 3.0 cause tremendous opportunity and tremendous disruption. Not all of the big companies of the dialup phase (Yahoo, AOL, Amazon, eBay) made a healthy transition into the mobile/broadband phase. And not all of the big companies of the broadband/mobile phase (Apple, Google, Facebook, Amazon) will make a healthy transition into the decentralized phase. Some will, some won’t.
In the venture business, you wait for these moments to come because they are where the big opportunities are. And the next big one is coming. That is incredibly exciting and is why we have these ridiculous valuations on technologies that barely/don’t work.
The Beginning Of The End Of White Male Dominance:
The big story of 2017 in the US was the beginning of the end of white male dominance. This is not a tech story, per se, but the tech sector was impacted by it. We saw numerous top VCs and tech CEOs leave their firms and companies over behavior that was finally outed and deemed unacceptable.
I think the trigger for this was the election of Donald Trump as President of the US in late 2016. He is the epitome of white male dominance. An unapologetic (actually braggart) groper in chief. I think it took something as horrible as the election of such an awful human being to shock the US into deciding that we could not allow this behavior any more. Courageous women such as Susan Fowler, Ellen Pao, and many others came forward and talked publicly about their struggles with behavior that we now deem unacceptable. I am not suggesting that Trump’s election caused Fowler, Pao, or any other woman to come forward, they did so out of their own courage and outrage. But I am suggesting that Trump’s election was the turning point on this issue from which there is no going back. It took Nixon to go to China and it took Trump to end white male dominance.
The big change in the US is that women now feel empowered, maybe even obligated, to come forward and tell their stories. And they are telling them. And bad behavior is being outed and long overdue changes are happening.
Women and minorities are also signing up in droves to do public service, to run for office, to start companies, to start VC firms, to lead our society. And they will.
Like the frenzy in crypto, this frenzy in outing bad behavior, is seeding fundamental changes in our society. I am certain that we will see more equity in positions of power for all women and minorities in the coming years.
The Tech Backlash:
Although I did not get much right in my 2017 predictions, I got this one right. It was easy. You could see it coming from miles away. Tech is the new Wall Street, full of ultra rich out of touch people who have too much power and not enough empathy. Erin Griffith nailed it in her Wired piece from a few weeks ago.

Add to that context the fact that the big tech platforms, Facebook, Google, and Twitter, were used to hack the 2016 election, and you get the backlash. I think we are seeing the start of something that has a lot of legs. Human beings don’t want to be controlled by machines. And we are increasingly being controlled by machines. We are addicted to our phones, fed information by algorithms we don’t understand, at risk of losing our jobs to robots. This is likely to be the narrative of the next thirty years.
How do we cope with this? My platform would be:
- Computer literacy for everyone. That means making sure that everyone is able to go into GitHub and read the code that increasingly controls our lives and understand what it does and how it works.
- Open source vs closed source software so we can see how the algorithms that control our lives work.
- Personal data sovereignty so that we control our data and provision it via API keys, etc to the digital services we use.
- A social safety net that includes health care for everyone that allows for a peaceful radical transformation of what work is in the 21st century.
2017 brought us many other interesting things, but these three stories dominated the macro environment in tech this year. And they are related to each other in the sense that each is a reaction to power structures that are increasingly unsustainable.
I will talk tomorrow about the future, a future that is equally fraught with fear and hope. We are in the midst of massive societal change and how we manage this change will determine how easily and safely we make this transition into an information driven existence.


