Topic Mining AVC
So I’m on sitting on the couch waiting to go out to dinner with the Gotham Gal and friends last night, and wasting time by scrolling through Twitter and I came across this tweet:
New Blog Post: Mining a VC http://t.co/BKJr43xhzq | Topic Model Analysis on Fred Wilson’s blog posts over more than 11 years!
— Bugra Akyildiz (@bugraa) January 17, 2015
I didn’t have time to check it out, so I favorited it and made a note to come back to it. And I did that this morning.
Bugra is a Data Scientist @axialco; he likes machine learning, data, Python and NLP, not necessarily in that order. He did some data science on this blog, starting on September 23rd, 2003, which is when I wrote the first post here.
Here is his post. It’s worth a full read but I’m going to gank a few images from it to summarize his findings for those who don’t feel like clicking over to it (you should).
Bugra mined 22 topics based on things I wrote most about and then did some analysis on those topics. Here is a frequency graph of them:
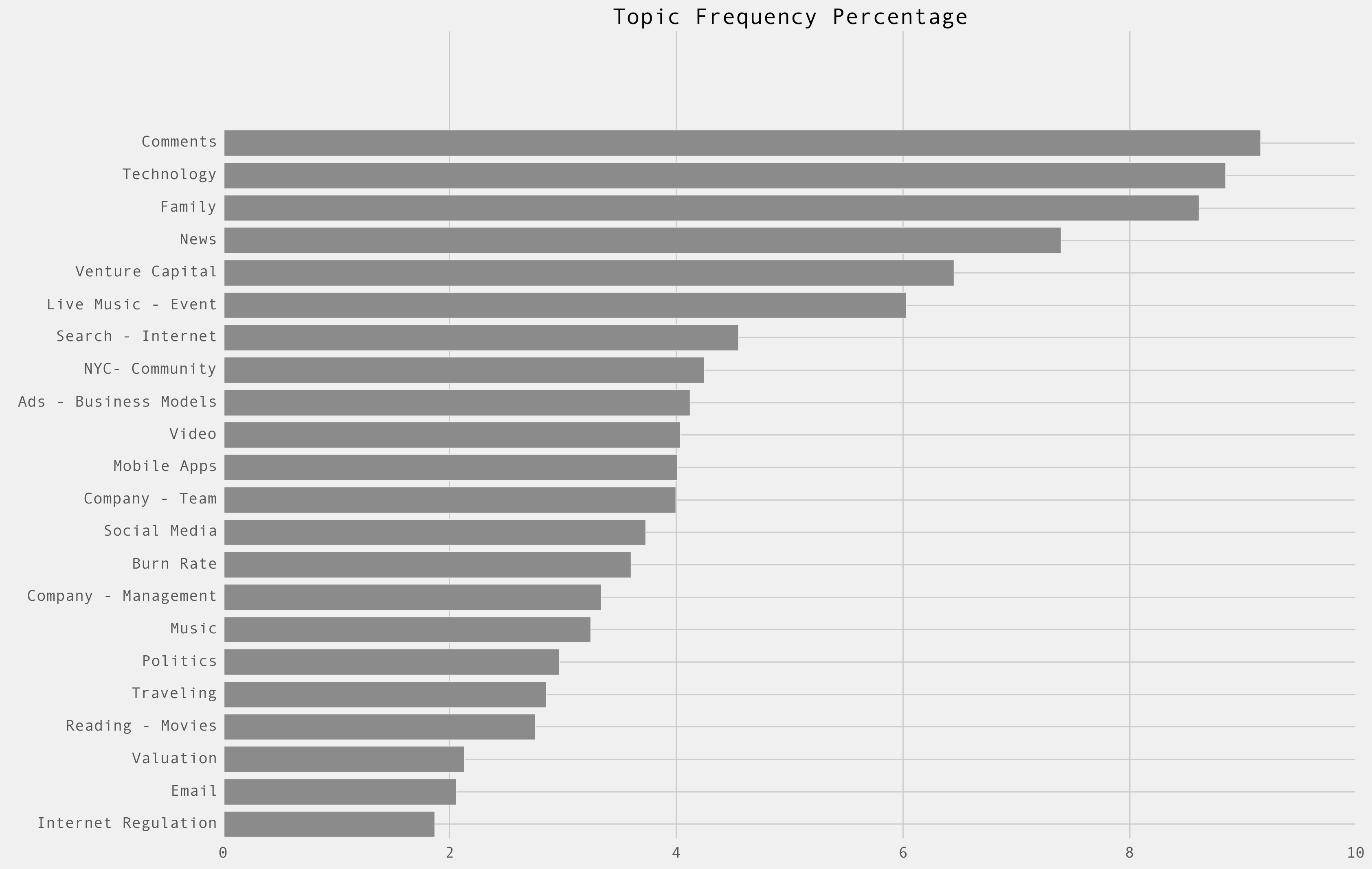
But of course my interest in these things rises and wanes over time.
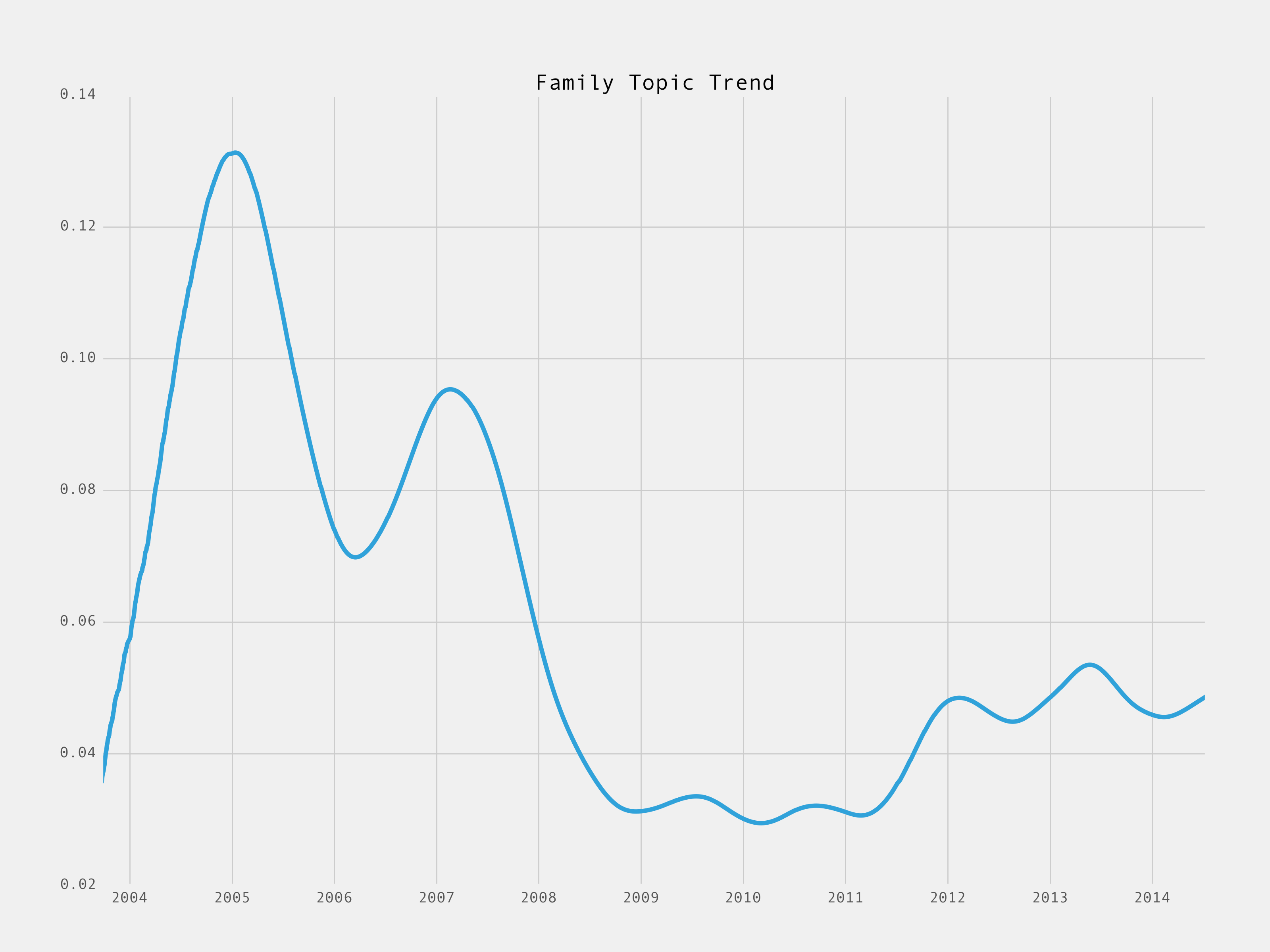
I mentioned at year end 2014 that I thought social media had become uninteresting. Well the data on what I write about proves that:

Sometimes it’s a lack of interest. But it could also be a conscious decision to stop writing about something. As the readership of AVC grew, it became a lot less personal. That was a conscious decision on my part.
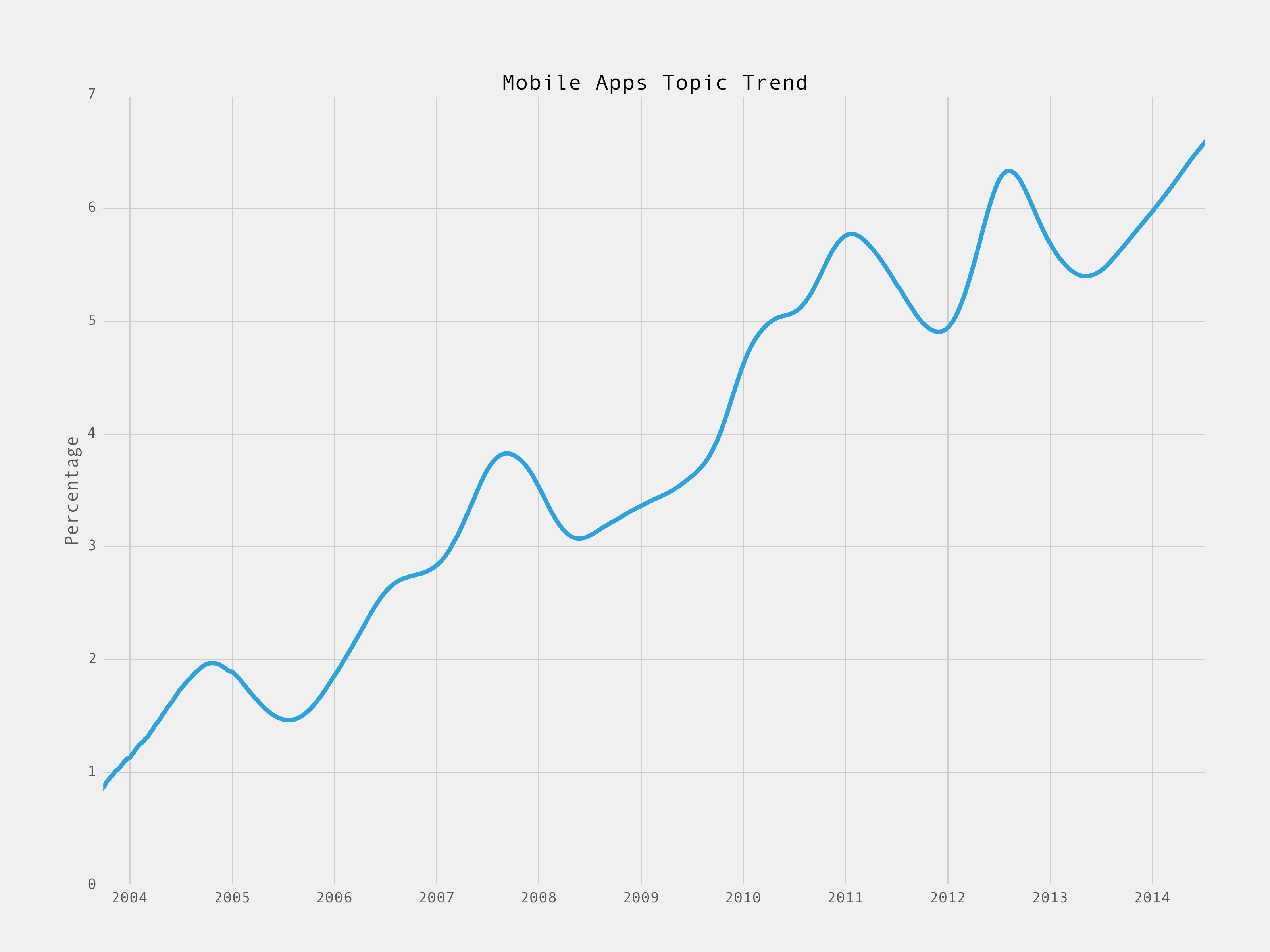
Not everything has gone down over time.
I’ve become a policy wonk (thanks to my partner Brad mostly):

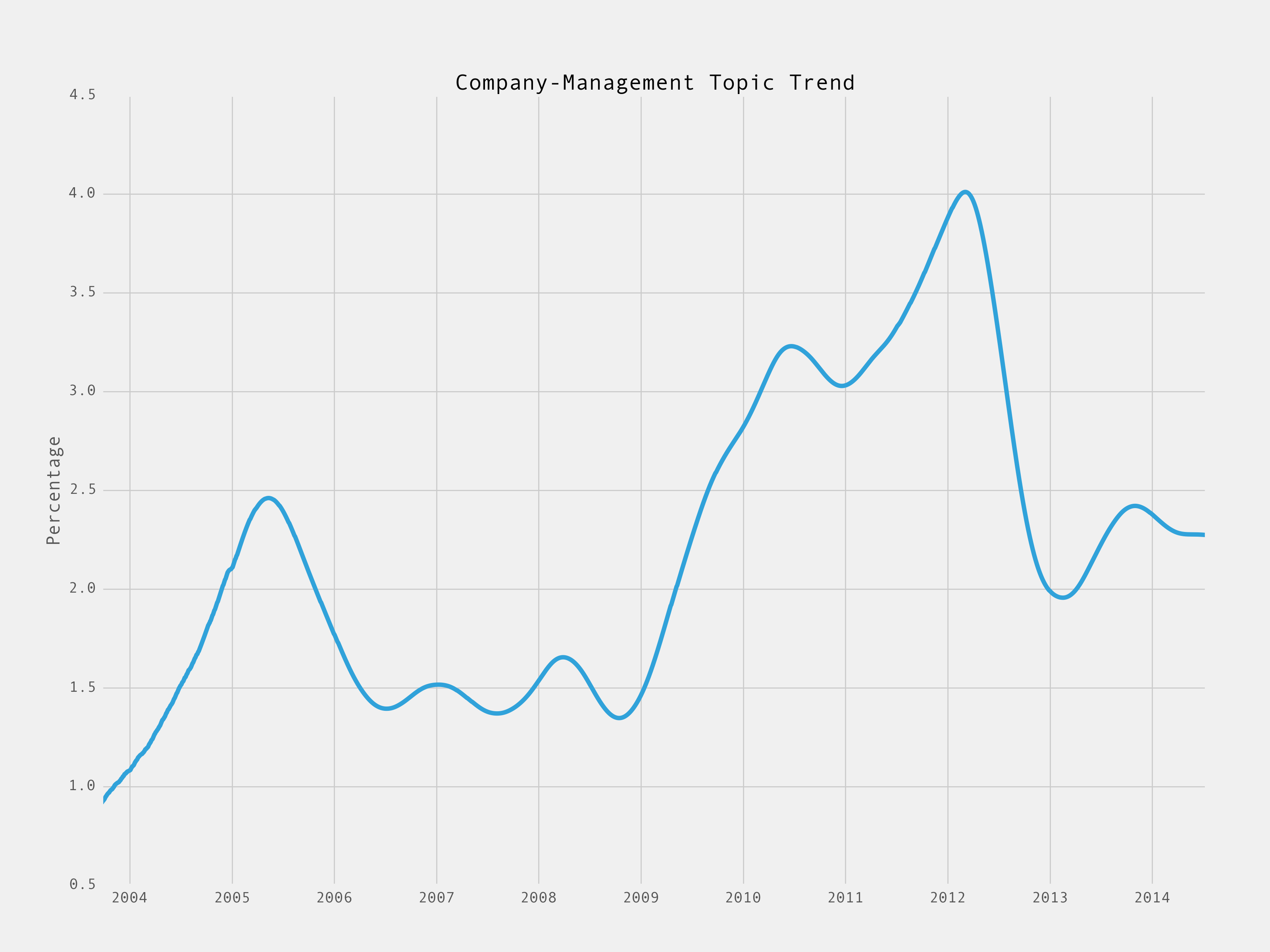
And some topics just reflect the changing landscape we operate in, like this one:
And some topics reflect the changing patterns of my blogging, like the rise and fall of MBA Mondays:
Anyway, I found Burga’s post fascinating. I would like to see him add a few more topics, like bitcoin/blockchain, education, healthcare, and crowdfunding. Those are all things that I think a lot about and I’d be very curious to see how my interest in them has risen and/or fallen over the years.
In closing, I’d like to thank Burga for his work. It is valuable and revealing to me. Thank you Burga.
Comments (Archived):
Mind blowing analysis.Feature request for Disqus to incorporate this into their Analytics 🙂
Yes, that would be awesome.
Disqus is looking for both an Algorithm Engineer and a Data Engineer. Here: https://disqus.com/jobs/
Hi JimFollowed your link as I know someone and came on this curious number.What does it mean?
That’s the aggregate duration of time readers spend on average each day with the Disqus comment section in the browser’s viewable port.Why does this matter? It’s a measure of aggregate engaged time which Disqus sees as a more valid measure than say, page views.
But what does engaged mean? For example… I spend more time on social sites when I’m bored because they are good entertainment. I’m *engaged* in wasting time not accomplishing tasks.
I think you answered your own question ;-)One can be engaged in trivial uses of their time, but they’re still engaged. It’s another way of saying, is the reader’s attention on this thing?Take TV as an example. Ratings or viewership numbers do not distinguish between “60 Minutes”, NFL, or reality TV when presenting the numbers. One can certainly draw conclusions about what people watched being some sort of reflection on society. But the point is, the metric of attention is valid. IOW, the numbers aren’t diminished just because one deems the quality of the media to be inferior.(The value to an advertiser might vary, but that’s a different, albeit related, issue).
One thing though about ratings or viewership numbers is that everyone has settled on one scale (Nielsen, right?) as the answer. So even if the scale is off [1] it’s all relative at least in one way.[1] Story of a butcher’s scale being off in a small town by a certain amount but it’s off for everyone and the only scale so nobody is really getting ripped off because the actual price is arbitrary.
I will assume that number doesn’t include the time that it takes someone to formulate and write a comment. You could easily calculate that metric and it would be a nice large and impressive number. And the more large numbers you can show the better for disqus. So in other words there are people that typically only read others comments and there are people that make the comments. Different types of engagement. The amount of time that some people spend writing comments, (or making jokes, some good some not so good) in some cases, would be quite large. [1]You could probably calculate the time it takes someone to write the comment by analyzing the time that the edit box is open. And even if you can’t (let’s say the engineers aren’t the “a” team) you can calculate that by words written.[1] Bigger than 9 inches in fact. <— Your serve….
To add that according to my “assumption of legitimacy” (and lazyness) nobody is going to question your methodology anyway. And if they do that’s fine more publicity for disqus.)
Knowing if those hours have been effective at helping them reach goals is what’s important..Think couch potato with the TV.
Lucky engineers! Disqus probably has amazing data corpus to play with.Hope they read this Medium post by Evan Williams on data metrics:* https://medium.com/@ev/a-mi…
Ev is getting a lot of run for that post, but it’s s but of a wank.On my FB is a list of my beliefs, including ‘Measure what matters’ from legendary Encana CEO Gwyn Morgan.Good point Ev makes – hardly a new one.
Post popularity is often because the concepts in the content are accessible to lots of people, which often means the concepts have been around for a long while and have seeped into widespread general consciousness.Plus Ev Williams is who he is: founder of Twitter and SV titan. So lots of product people and engineers out there will pay attention to his experiences.There wouldn’t be so much run for a post where he was writing about KPI (key performance indicators) for space rockets because:(1.) Not as many of us are going to be building space rockets and, therefore, have a vested interest in learning about their KPIs.(2.) Evan Williams doesn’t have the same cachet as Elon Musk would, writing about rocket metrics instead of social media metrics.A lot of business metrics are indeed borrowed from the scientific sectors. Einstein introduced the concept of the relativity of time and the ideas of vector spaces has been around for ages.Lo & behold…….Big Data, social networks and AI all metrify relative time and put data into vector spaces to calculate the relative correlations between them.So…hardly new, just tools cross-applied from one discipline to another.
Awesome feedback for someone that writes a blog. How to turn it into a B2B business that creates increasing sales numbers would be interesting to think about.
It is rear view mirror-ish, but very insightful indeed.
This type of analysis is done frequently and soon enough after publication of a post that ad tech uses it to contextually target.
Done by whom- Disqus internally for your publishers-clients?
Yes, we’ve analyzed the articles and the comment threads for context. But we’ve also used third party service providers. Zemanta has these capabilities, Peer39 does this, I think. And I’m pretty sure the DMPs do it.
Maybe if the B2B business can pinpoint which commenters are biggest influencers (sales leads).
was thinking more broadly. what if you could predict future sentiment and tailor a sales pitch to customers based on data like this?
Sentiment understanding is hard technically. Text mining for topics is comparatively straightforward and established knowhow.There are companies like Crimson Hexagon and Kanjoya (based on 10 years of Natural Language Processing research at Stanford) and others which try to do sentiment parsing of text.Here’s the state of play:* http://giladlotan.com/2013/…At the roots of the problem are the limitations of probability for filtering and understanding words (never mind sentences).
Takes humans to interpret the data, make inferences, and create a pitch that utilizes the data!
Haha, have you seen the memo from Google yet?They’ll soon be our brains. What do we need human interpretation for? (said with tongue-in-cheek, :*))* https://medium.com/backchan…In finance, the machines have been interpreting all the data for decades: “Somehow the genius quants — the best and brightest geeks Wall Street firms could buy — fed $1 trillion in subprime mortgage debt into their supercomputers, added some derivatives, massaged the arrangements with computer algorithms and — poof! — created $62 trillion in imaginary wealth. It’s not much of a stretch to imagine that all of that imaginary wealth is locked up somewhere inside the computers, and that we humans, led by the silverback males of the financial world, Ben Bernanke and Henry Paulson, are frantically beseeching the monolith for answers. Or maybe we are lost in space, with Dave the astronaut pleading, “Open the bank vault doors, Hal.”As the current financial crisis spreads (like a computer virus) on the earth’s nervous system (the Internet), it’s worth asking if we have somehow managed to colossally outsmart ourselves using computers. After all, the Wall Street titans loved swaps and derivatives because they were totally unregulated by humans. That left nobody but the machines in charge.* http://www.nytimes.com/2008…
Yup, and some people faded it and made billions. They went against the herd, thought out of the box and refused to believe the confirmation bias. There is no substitute for the human brain, human creativity, and critical thinking.
Agreed.The risk isn’t in us using the machines as an additional tool to gain perspective — particularly when they can process complex maths faster and for longer periods than our brains can.The risks happen when we hand over all human decision-making to the machines and without supervision.They’re simply not yet intelligent enough to be able to contextualize and understand the nuances in information in the way our brains can — particularly wrt language and information about non-quantitative events such as changes in legal and ethical frameworks and in human relationship dynamics.
Good read indeed!
“We can more or less know what you’re thinking about.” — Eric Schmidt, Google.”Your personality, your skills are contained in information in your neocortex, and it is information. These technologies will be a million times more powerful in 20 years and we will be able to manipulate the information inside your brain.” — Ray Kurzweil, Google.* http://www.marketplace.org/…And then watch ‘Hybrid Thinking’ with Kurzweil:* https://www.youtube.com/wat…We think about mesh networks as our wearables all enabling P2P connectivity.Google thinks of mesh networks as neurotransmitters INSIDE OUR BRAINS (!) that they can pipe their information into.Topics categorization isn’t where Google is on the Data Science and Machine Intelligence curve for sure!
http://www.bloomberg.com/ne… Singapore based company is helping UBS out with exactly this!
Thanks, v. interesting! Not surprising, that it’s derivatives programmers who are doing the modeling.About 18 months ago I was looking at some quant research papers on Oil Derivatives and thinking through some of the “latency energy” issues there.Then someone in the Deep Learning community pointed me to the work of Alex Wissner-Gross, the quantum physicist who’s trying to come up with a General Universal Equation for Intelligence. This is something of a Holy Grail for Quantum Physicists and AI researchers alike.This is Wissner-Gross’ version of what he believes to be as important as Einstein’s E=mc2: F = T ∇ Sτwhere F is a force that acts so to maximize future freedom of action, to keep options open with some strength, T with S, an amount of diversity to possible accessible futures, up to some future time horizon, Tau. And he mentions latent energies too.In any case, I came up with another equation which factors in what none of the current models do: the biochemistry of perceptions (a qualitative+quantitative metric).In private wealth management, it’s not enough to measure the quantitative factors of the commodity (even with “Big Data” inclusion of edges such as social media “likes”, behavioral activity on prestige sits like chanel.com etc) to base a product recommendation on.The quality of lifestyle the client wants to project / preserve is a latent factor that the algorithms can’t currently surface or measure.____The qualitative dimension is what would enable the solving of the sentiment piece too, imo.
“…and we will be able to manipulate the information inside your brain.”.But won’t that only apply to the low intelligence people who don’t realize someone is trying to manipulate them? Once a person realizes what’s going on then they will no longer fall for it.
All of us are manipulated by the systems, regardless of whether our level of intelligence is low or high. A/B testing is a classic example of that and there’s nothing wrong with A/B testing per se.We want to get to content faster and for that content to be relevant and of interest and appeal to us. So, in reciprocity, the systems channel us towards it.Google’s vision of being able to manipulate the information inside our brains is a different case from A/B testing.
Important to note that A/B testing only shows us that certain treatments can manipulate some people, often a good portion of people stick with their default behaviors.
True, but if you have the pool of default (which expands across low/high intel/income) behaviors you change the default in so many. You then change so many more in the next round and so on. Couple that with Accelerated Returns and you change/introduce new defaults.Another integer in the equation not being discussed is the exposure to the technology and increased time connected to the cloud/web.
I thought people generally resist change because it scares them?
True, but marketing already herds the animals anyway and they love it
With an AB test they may not notice the changes enough plus there is always the tendency with all tests to regress to the mean behavior
You can out beat AB tests easily. Most people don’t bother because explaining why is a hard sell when people barely understand AB tests.(let’s put it this way, I have some crazy texts on the subject about tools better than AB testing from one of the best data scientists in NYC, in which I highly disagree about how sellable his idea is. Which the tool would be vastly superior to an AB test)
What do you mean by “beat”?
I swore on my U of C “Where fun comes to die” shirt that I would speak no details about how it works. I have deep loyalty to my college-mates that I am only barely realizing, since many stuck by me through some serious bad things.(reference point: http://www.noggblog.com/wp-… )However, for a basic idea of how difficult something better is to sell something better: 99% of stuff that changes in an AB test are things would not be permanent brand based permanent changes anyway/full design changes that would be stuck there for a year or more, and probably would be better of being tested in a bandit algorithm on a continuous basis. The same thing is true on low traffic pages. Furthermore, for high traffic sites, you should seriously just invest in a data person/team/stuff for personalizations/through the funnel stuff, but explaining why is going to be a nightmare to about half the business side. Explaining why though would mean explaining through the mechanics of an ab test and then explaining why anything else is better Most marketers still don’t understand the philosophical issues behind the mechanics of an AB test (even I don’t understand all of them) (I’ve been in situations where are least one major player in an analytics/business intellegence team in a publisher did not understand the difference between correlation and causation, or understand why you can’t interrupt a test mid-run, so trying to explain all of the above would have been beyond this person without really lying to this person)
Or as someone at one of my jobs would once summarize it: you people and your fancy university degrees ;).The kids at optimizely found a model, and most e-mail marketing software now has A/B testing or some variation. It’s not easy to sell something when people lack subject matter expertise in it, but maybe instead of trying to sell people on a better mouse trap they should just focus on selling mouse traps generally. 🙂
a) optimizely’s founders have fancy degrees too. Dan Siroker is a Stanford Grad 🙂 The technology was spun out of the obama campaign 2008 – so, there is that going for it, and that campaign was very public about numbers equally donor money and winning.Me swearing on a shirt has nothing to do with the fanciness of the degree, just loyalty to people. Been one of those months.b) The open secret:the math for most of these products, including optimizely, is slightly off so people use will use the products. So they may not be selling the mousetrap you think they are selling, as a general rule.c) I’m not sure we’re selling mousetraps. The thing is, I don’t think we have a tendency to keep ourselves on top of what is really happening around us. Also, considering how they are sold, I think in part they are holding marketers back and treating them like they are dumb – which I personally find a bit offensive to the buyer. Marketers are not dumb.
The thing is, can we notice the system?
The question that popped up in my mind is “But does it create real value above and beyond the people getting paid to do the analysis and create the algorithms?”
And yet, for most things, crimson hexagon is still better than nothing
So…the thing I OBSESS about is natural language understanding and that includes the space of text-mining, semantic analytics and opinion clustering.Now, I have a reasonable insight on what tools are available and what they can/can’t do as well as the roots of why the machines haven’t been able to understand language or sentiments (please see graphics).Fred talked in his Seedcamp video about “being bored with everything.”I got bored senseless with the same old-same old “echo chamber” approaches in Machine Intelligence and particularly in Natural Language and sentiment, so I decided to code my own system and filed a patent.Stanford’s Sentiment Treebank released in Q4 2013 is based on a combination of Noam Chomsky’s syntax work from 1957. The researcher involved raised $8 million seed from Khosla Ventures and Salesforce.com chief executive Marc Benioff to launch a startup just last month.The structure of Harvard General Inquirer has been around since 1961 as an IBM 7090 program system that was developed for content analysis research problems.So…….this is why I need to be in the States because to fundamentally change Natural Language structures that will enable sentiment analytics, text-mining etc.The changes have to happen with the corpus structures of Stanford, Harvard, Princeton, Carnegie Mellon, MIT etc.______pointsnfigures William Mougayar JimHirshfield David Semeria may also be interested in this.
So parts of stanfords was beaten by berkley’s this year.And I have something on the web that I want to say, but I promised I wouldn’t. Oof. Oof. Oof.
How does being able to predict future sentiment allow you to tailor a sales pitch to someone? (I might be misunderstanding what you are saying). In terms of sales it’s typically very easy to tailor a sales pitch by hitting someone’s hot buttons. That is things they are already thinking about not things they don’t know or don’t currently care about. That’s very difficult because it’s not a front burner issue. And it’s not on their mind.For example let’s say you knew 8 years ago that computer security would be hot 2 years down the road (from 8 years). So go ahead and try to sell that. vs. selling when it’s on everybody’s mind and a hot button.And there are many dynamics. Such as if something doesn’t seem important then you can’t get people to make fast decisions and take action. It becomes something that isn’t important in the present and not going to be decided until they get the fictional “round tuit”.http://en.wiktionary.org/wi…
I’ll let @pointsnfigures:disqus explain what he’s talking about. However, if you move over to customers as public at large and tailor/produce/implement messages that would be reaching them at time of peaked interest (that you predetermined) you have something.
I guess you could be ready “just in case”. But actually predicting the future is not something to count on. You can keep feelers out there waiting to get indication that “it’s here”. But going all in on something that you think is years into the future might not be good.
True, but as in things ML, we’re talking of odds. So if you have a threshold you can use it. Remember more real time analysis like with hashtags and so on will be commonplace
You say “that you predetermined”. How long is the prediction of the coming window of opportunity good for and if/when the window appears how long is it open?.We have to know those things so that we can ensure we can take advantage of the window before it closes. So lead time to tailor/produce messages. Money we can make as compared to preparation costs. Etc..Much of today’s web “fads” come and go so fast you can’t take advantage of them. So again predicting far enough into the future to *be able* to take advantage of the prediction carries with it huge risk.
I’m referring to windows of 3-4 days so you’d have the threshold and time to implement message/ad and so forth. This is 3 years away give/take 6-10 months
Right. You can take on the task of educating the public to your way of thinking. That can take huge amounts of time and money. Or you can wait until something is hot then jump into aggressive selling..If you can get the funding it’s best to be first and do the educating. But without huge funding it’s much better to wait and copy.
Hey… That’s a topic worth exploring!
How to turn it into a B2B business that creates increasing sales numbers would be interesting to think about.The easiest way is to get a few large customers onboard (even if you have to give the product away for free to them) and then use that to convince other large customers that their customers use the product. [1] [2] Notice how I am not even talking about whether the product has any real benefits. (Of course if it does that would be nice.) As such the product page has to talk about large companies that are customers (even if those customers are just a very small department of a large company). Not the usual dog and pony show of startups that large companies don’t care about. You know those “trusted by” pages that you always see. Which only mention startups that geeks care about.[1] So hey, it must have value.[2] When selling to a business often the easiest way to close is simply to point out that a well know competitor uses the product.
If your dad’s military background taught him God, Country, Family…I guess it makes sense the A VC version is Comments, Technology, Family 🙂
ha
Thanks for the kind words, it was a pleasure to write the blog post.For other topics like blockchain, crowdfunding and such, I guess I need to limit the time interval of the blog posts for the last 3-4 years. But that would be definitely interesting to see/analyze those topics.
@bugra – Well done. Compelling. Would this work in informing, the chief knowledge officer of, for example, IBM or Accenture or the US Army, of what topics are trending across messaging platforms (email, blogs, Twitter, social, texting, search etc.) ? I would think, with the right permissions, that it would and be a valuable source of understanding what is happening within a complex organization. Is this right?
But without the objectives to compare it with what is the value? One thing I want to say is that entertainment is a valid objective. But how can you know if people are just bored and wasting time without know what their objective is?
One thing I want to say is that entertainment is a valid objective. Nobody is going to acknowledge that the value of something like this is entertainment. What they will do is figure out some rationalization of the value and then everyone else will just nod in agreement that it must have some value. However as the saying goes “garbage in garbage out” so I wonder how often people who use or pay for data like this will actually vet the methodology in any way.But how can you know if people are just bored and wasting time without know what their objective is?Part of the problem is the echo chamber effect. [1]The question is when does a business concept become actionable? By the time it shows up and is on the radar [2] everyone already knows about it. As such it would make more sense to simply hand roll your own techniques [3] to uncover info needed for business decisions. Which really doesn’t take as much large scale analysis as people would think.I will take a stab here and say that some hedge funds already gather data in a way that allows them to spot things way before they are mainstream knowledge. Because that is a well oiled machine with immediate feedback and they can’t afford to be wrong anywhere as often as a VC is wrong.[1] Below is the google trends for a particularly annoying phrase (to me at least) “just sayin” which took the world by storm back in 2009.[2] Extreme case might be NY Times writes about it.[3] As an example a network of high school teachers all across the country who are polled every month to find out “what are your kids talking about”.
Yes, you could measure trending topics across different platforms using topic modeling but topic modeling generally works(in my experience) well in longer than medium length posts. For tweets, one needs to be more careful on the feature extraction as the tweets are very short (at least comparing to blog posts).Right now, I know that Twitter uses topic modeling based filtering approach to show what type of tweets you would see in your timeline(so called “algorithmic timeline”). Details of that approach is in this paper: http://www.eeshyang.com/pap…(which is a great paper on its own; in terms of research, writing and implementation level details)
I think, after looking at the analysis for MBA Mondays, you should have continued giving time to that venture and you would have doubled the precentage trend again.
I just needed to research “is Ruby scalable?” … i have my view but needed to seek other points of view… it would seem to me that bugra’s play here would be able to trend toward a conclusion v. what I just did giving the exercise 10 or so minutes… could it be in the future that if you have a question like this that you type it (into a search engine) and get a trend graph something like the ones Fred’s comments inspired?
If it works for Apple, AirBnb, Hulu, GitHub, and Bloomberg I think that you can probably figure it out. 🙂
Double Top break out on Mobile apps. Reasons – intuitively obvious. Is there a convergence/divergence or correlation of portfolio deals historically in each topic area to given points on each relevant curve? (Topic boom-Topic bust?)Does the interest fall off the further away the further participation gets in funding, board participation, exit, etc. Rhetorically posed as an interest in the influence of behavioral impact of topics, length and enterprise building. Great post even for the pseudo-techs…
This reminds me of what the back end of TheGrid.io must look like. I suppose when using AI, then it’s like the subconscious, albeit and actionable, algorithmic one.
The Minnesota legislature just introduced Equity Crowdfunding legislation – joining a whole bunch of states that passed similar bills last year. I would be interested in the thoughts of the group.Link to Minnesota news: http://www.crowdfundinsider…
Interesting analysis. I’ve been going through John Foreman’s great introduction to algorithms, Data Smart, over the past few months. Information on the book is available at: http://www.wiley.com/WileyC… and the nice thing about it is that the examples are all done in Microsoft Excel so that you can see and better internalize how the algorithms are working.While the output of the analysis is interesting, I do not see a whole lot about how and why this sausage was made. How does LDA work and compare to using say, naive bayes? Did it automatically generate some kind of clusters that he had to then go back and label, or (it appears) that the algorithm automatically generated topic labels? Is this an R package?
Fred, I think you and Burga should point out more strongly his analysis is not based on your manual tags for each post (as was my initial impression) rather it’s based on actually mining the text.When this is clear, Burga’s analysis of AVC becomes much more interesting….
Cool stuff. I agree with this: “I mentioned at year end 2014 that I thought social media had become uninteresting.”.Boy is that the truth..But I also think you’re reading too much structure into the data. If your posts were intentionally planned, over say a one year cycle, then you could conclude more from the data. I think what you’re seeing there mostly is just plain randomness.
Very nice analysis. It speaks much that up/right and at 12% of posts currently, NYC – Community is the #1 topic given the other wealth of info shared here… also will be interesting to see whether music + multimedia posts grow in aggregate in 2015. Well done.
Here are the public companies behind the brands and products Fred tweets about most: http://likefolio.com/fredwi…Just put your own Twitter handle at the end to check it out further.
“Most Mentioned Companies”.Where does this data come from and who is behind it? (You of course I figured that out from your linkedin because it sounded familiar).As far as “where does this data come from” missing from the home page (root page redirects to here: http://likefolio.com/f/lf-l… ) is exactly where this data comes from. That’s important as well as who is behind the site.Also, the infinite scroll means if there is any footer info I will never see it.
“Where does this data come from and who is behind it?”.That’s one of the most important questions to ask about information especially information on the world wide web of deceit.
Graphs can be very misleading, look at the y axis of some of the plots. Social media for example covers 1/2 of 1%.
Funny this reminded me of this keyword analysis we did for you in 2011 (from Eqentia) based on about 1,000 comments from a single post on Occupy Wall Street. Some good stuff in the middle.
Thanks for sharing this graphic. I hadn’t heard of Eqentia before and now I’ve found some articles on Engagio.There’ve been topic clouds, text mining, cluster graphs of words as well as maps of tweets and word frequency for countries.It’s going to be interesting to see what the Disqus engineers do with their corpus!
The algorithm choice causes significant overlaps in topics, especially because of linguistic and role shifts of people, companies and points of view, that I don’t think the charts are capturing accurately. While I do see them as partially accurate, I wonder if there needs to be something added to model that shift (just based on the groupings popping out)
Thinking about it, this should have been supervised rather than unsupervised
I still miss your posts about politics, particularly presidential politics. But I get why you stopped writing about that.
i still dothis was from a couple months agohttp://avc.com/2014/11/immi…
10 years of data shows very interesting lines. Hope this guy looks at more topics, well done!
From what I see media and communications with Twitter etc. needs to be stressed within an organization. For myself, During the day I put what is most important first and analyze how to implement a system to have this information input on a daily basis. Only thing I can see is having the right employees to make sure this part of the business is kept up with that way nothing has been missed.
Here are the public companies behind the brands and products Fred tweets about moshttp://tandatandaoranghamil…