400,000 Followers
I got a notification from Twitter last night that I had passed 400,000 followers. I don’t pay much attention to my follower count on Twitter but I did pause at that number. It’s a lot of people.
In light of this milestone of sorts, I thought I’d share some details on the people who follow me on Twitter. All of this data comes from the analytics service that comes with every Twitter account.
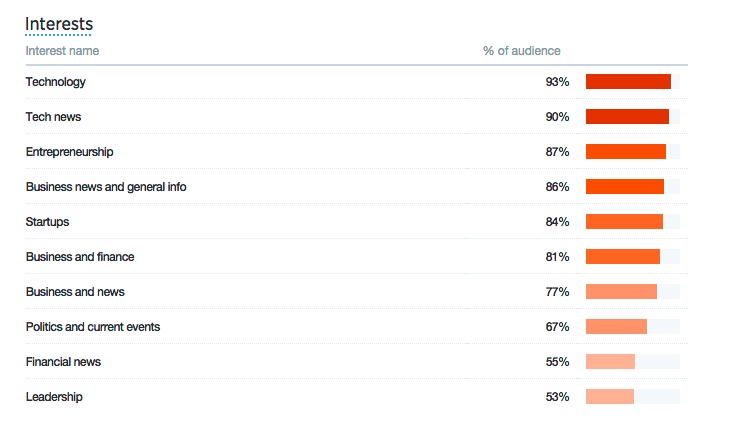
Not surprisingly, my Twitter followers are interested in technology and startups:
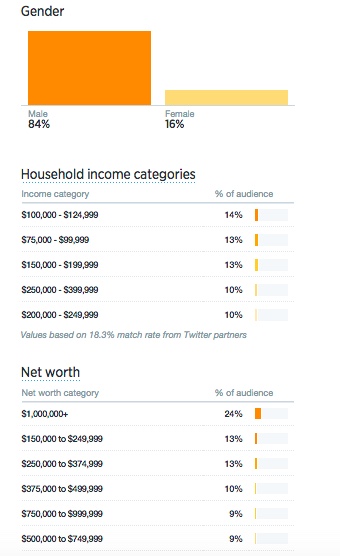
They are overwhelmingly wealthy men:
They lean democrat

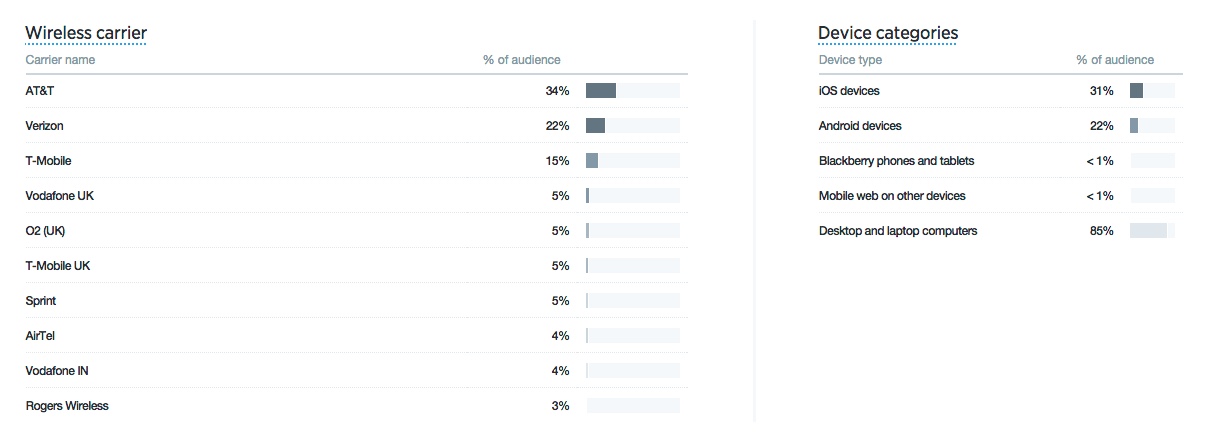
And they prefer iPhones:
I’ve run these sorts of analytics on the readers of this blog and the results are pretty similar. Similar size of audience, similar demographics, interests, and mobile preferences.
If I had a wish, it would be for a more global audience, a more female audience, and a broader demographic in terms of wealth (or lack thereof). But the content I produce determines the audience. And I’m pleased that all of you are interested in what I have to say and I’d like to thank you for listening.
Comments (Archived):
What about a catergory for read only?
Huh?
Non-commenters, is what I think he means.
Yes, thanks.
Interesting. How many of us are outside the US?
Not that many. Maybe 10% to 20%
What about US geography?
I resemble a few of those demo/psychographic segments; I’m just not gonna say which ones 😉
In this day and age it’s only about what you feel in the moment.
Would you be as open about releasing metrics for your blog? That’d be interesting too.
That’s an annual occurrence around here, like unwrapping the toys at Christmas. Should be due for an update soon.
I’ve been on daily since March 2014. Hasn’t happened yet in my “tenure”.
Maybe it’s a leap year thing?
I will do it tomorrow
Oooh, Christmas in July.
Out of curiosity would that capture people like me who follow via Feedly>IFTTT as opposed to a direct follow?
it happens when it happens. Then it turns out we navelgaze about it, and think about how analyitcs is failing us in general, and where tech is going by the numbers.Actually, interesting would be historical comparisons from ages ago! Was there more Digg? What iphone!cc: @fredwilson:disqus
CNN or MSNBC wish they had those demos. Not FOX though, too democratic. I see high CPM’s in your future 🙂
I’m one of the 16% and outside of the US too! Woo!! I’m working on your wish Fred; I always recommend your blog to like-minded ladies and gentlemen.
thanks. pls keep doing that
Yay! You go!
One of the 16% — has a certain ring to it!
I will start the pot stirring a bit I suppose… obviously everyone (of all genders and income etc) are free to read your blog, but there is a distinctive trend. I think partially that is a refection of ambition / greed / competitiveness. To be 100% clear, the gap in white men leading entrepreneurship should NOT be as large as it is, but I am not 100% sure that especially when it comes to gender it will / should be 50% – 50%, as for certainly cultural and perhaps biological (testosterone and other risk taking components of the brain) men seem to self-select more for most wild successes. Again, I have caveated this as much as possible to avoid a flame war, but it is at least an important thing that intellectually curious and honest people can discuss
How about discarding that pot Matt. As a simple example, spend some time in the developing world and witness hundreds of millions of women running their own businesses. Entrepreneurship is not the same as risk taking – although the glut of investor cash is turning it into gambling for some.
Well it depends how you define entrepreneurship I guess. In the context of building $100M+ society transforming businesses you sure as hell are taking a risk. And that is what I am focusing on and saying you need insane ambition (mind you this may not even be rational.. or desirable). Starting a mom and pop business has nothing wrong with it, and in fact there I do think the numbers are very similar in the US on gender (which partially shows the society isn’t massively gender discriminatory I would offer since it hasn’t stopped smaller businesses). And you are very right in the developing world. In fact greater financial and educational resourxes for women in developing economies is great policy
Yes, it’s interesting the gender split of Fred’s readership reflects the %’s in the diversity in tech issue.16-18% is about the percentage of females in a technical role at the major startups and techco’s in SV.There’s some self-selection that happens. However, there are also more subtle factors at play — such as topic selection and language used.We may also discover that more women than men tend to be lurkers rather than commenters. This would reflect how women don’t speak up and make ourselves visible (sometimes because of lack of confidence, self-consciousness etc as much as feeling disconnected from the topic and, therefore, it not being valuable enough for women to add their views to.).That’s why I especially love it when Shana, Donna, Ann, Kirsten et al comment and contribute their 2 cents!
Yeah, I definitely like and enjoy vigorous debate with both genders. My biggest point in fact is that is what we need more of is competitive or aggressive women. And I agree there are cultural norms that make it more difficult on women, but the solution is not to ask men to be less aggressive. Will not happen. Its to say anyone / everyone needs to be very aggressive, yet constructive and polite in talking about and advocating and in competing on everything
Ok I have to say those aggressive, bolshy, male-bashing women in the world really do neither genders any favors. Just as the aggressive, bolshy, female-bashing men don’t either.Reason backed by research, data and source links that support and/or challenge a position increases the gravitas and value of a person, regardless of what their gender is.Aggression is often used as a substitute for substance and sensible consideration so it should be avoided.
There are a subset of people that seem to believe that by adopting the worst traits and habits of successful people they too can be successful. Awful idea!
You’re way off on the gender competitive thing.You’ve obviously never spent time around a group of girls . They can be fiercer and more competitive than men . They don’t need testosterone . They use their brains , their networks and their charm . They choose where to play, where to focus and where to compete . If they are not around , it means they choose not to play . They have given their time to doing other things . If you want them around , you need to understand them and what they need.
as a father of two daughters, that is so true. They compete in different ways-and use very different language.
They can be fiercer and more competitive than menOne thing that I have noticed about woman, and this is from both personal observation and popular culture (say movies, TV and so on), is that men seem to want to follow and be friends with the alpha successful male “rub off on me and learn his secrets” however women tend to be more jealous and put off of women who have more than them.If a man sees a guy with a beautiful woman, a nice car, a big house, or a large bank account, he is typically drawn to that man and wants to know his secret and tries to befriend him. A woman (once again this is my observation anyone else is free to comment otherwise) tends toward being more jealous and perhaps even back stabbing of that female. Not saying this is always the case but it is the case enough that it stands out as a difference (to me anyway) between men and woman (at least among lemmings).
“Men seem to want to follow and be friends with the alpha successful male “rub off on me and learn his secrets” however women tend to be more jealous and put off of women who have more than them.”Sadly, this can be so true.The unnecessary “Mean Girls” thing can really hold women back.Healthy magnanimity in celebrating and learning from the success of others, regardless of gender, is the way forward.
I don’t think it’s smart to generalize for billions of people. If you have any data to support your views please post it.
One thing I like about how @William Mougyar and other guys/gals ask for stats is they do it in a really polite way so as to keep the conversation going and not make the other person feel shut down. Good-natured challenging raises the level of conversation, which I think is what you’re after.
I would say the burden is on Matt for that one 🙂
Marissa, in all due respect I have spent massive amounts of time around a group of girls. I had a very large cohort of female friends in high school, and of my five closest friends now 4 are women, and all very competitive and successful financially and personally. But they are more on the outlier in terms of demographic trends.
competitive momming is a thing (I can see it on facebook)
Thank you. I didn’t even know where to start.
we do have testosterone, but I think why competitive isn’t just a hormone thing in either biological sex
So here’s the thing: if you’re really interested in understanding the current state of female presence in tech and entrepreneurship, you need to educate yourself.There’s just not enough room in any comments section to bring you up to speed.So often, when the idea of gender diversity in tech or business gets brought up, someone feels the need to beg the question. Then, instead of creatively coming up with things to move us forward, we bog down in “Are women REALLY cut out for tech?” That’s when a lot of women tune out because (i) we’re super tired of explaining it over and over, and (ii) anybody who’s really interested in learning that answer would be willing to go out educate themselves.It’s like me showing up on Stack Overflow Python and answering people’s questions with, “Why are you using Python? Let’s discuss why you chose that over Ruby.” Or even, “Why are you even a programmer? Shouldn’t you be in PR or marketing?”
Amen. Encountering the eternal sunshine of mapping assumptions about gender to certain traits (competitiveness, jealousy, etc), enhanced with anecdata is tiring. These traits are typically evenly distributed in both genders, albeit expressed and labelled differently, in accordance with the prevailing stereotypes of the context (location, culture, etc) in question.
Ok so I made a decision not to contribute to the same-old-same-old vicious circle of debating the “Pipeline Problem” (a red herring if ever there was one).A decade ago I experienced a little of what Tracy Chou of Pinterest is experiencing. I was invited to keynote talks on ‘Women in banking technology’.A decade on, the inclusion in tech issue remains as stagnant as ever — ok except the techcos are starting to collect and publish data on it.That’s an INCREMENTAL change not a transformative one.The transformative one is where female founders, who are also coders, do what the likes of Elizabeth Holmes of Theranos is doing: INVENTING, BUILDING & SHIPPING INNOVATION.We’re going beyond a world where women are line engineers or even CTOs running big teams for someone else to one where women are founding, leading, inventing and shipping systems.So that’s where my own personal curve about the whole inclusion in technology issue is.It’s why I returned to coding. Otherwise, I’d have a nice corner office job analyzing people’s business plans and helping decide investment “Yes / No.”
So two thoughts. 1, I don’t exactly think I am uneducated on this topic. I reject that categorization. We have had numerous back and fourth on this topic as well as with many other women. I follow gothamgal’s blog too, I read modelviewculture, and I also read / follow multiple feminist blogs. It is fair to say you disagree with my opinions or interpretations, but not totally fair to say uneducated. So happy if there are other links or opinions that you want to share, because my history in fact is one of being open / forward looking. My real take away is yes there are cultural / structural factors / industry factors, but one of the largest is simply a brashness / aggressiveness / confidence factor that is a must to succeed in a competitive industry. To make myself 100% clear, women intellectually can compete with men on equal grounds. 100%. The gap is primarily in this aggressiveness / self-promoting / confidence side. Is that partly biological or is all just cultural? That is what I am questioning, and more importantly saying that is where the effort needs to focus. There is this narrative that elite business / science / computing needs to become less aggressive etc., a) that won’t happen b) that shouldn’t happen. What I am saying is lets stop making competitiveness / aggressiveness a male thing (from the stereotypical side … because obviously some women do this, just at a lower % statistically as of now.. hence the largest reason for the gap in my opinion), and make that “competitive greatness” the goal for everyone. Agree /disagree? And I welcome debate and opinions, but categorically reject that I am uneducated on it, that is simply used to shut down debate in the same way you say women are tired of discussing the topic. Can I be further educated, I am sure. That is why I commented, and am replying here. But very untrue and unfair to say uneducated as your comment implies, especially in light of my engaged commenting history here.
More female audience => more coverage on female-led startups outside of current AVC portfolio?
good suggestion
Why would more coverage on female-led startups lead to more female viewership. Its equivalent to saying that techcunch could increase its female readership by writing more about Marissa Mayer. Like men, females too value great startups irrespective of who started it. What am I missing?
Firstly, here’s Nikolai Tesla.Secondly, here are some female-led startups which aren’t in USV’s portfolio that are doing seriously cool / smart stuff:(1.) Theranos(2.) Affectiva(3.) Emotient(4.) Houzz(5.) 23&Me(6.) Joyus(7.) AllVoices(8.) Obopay
great listjust shared it with the gotham gal for next year’s WE Festival
Thanks and Affectiva & Emotient should be shared with Albert Wenger for Machine Intelligence.The hardest problem to solve in AI is around emotions — in visual recognition as well as in Natural Language classifiers for understanding the meaning of our words online.And it’s women who are leading the way in solving those problems.
Affectiva and Emotient are well-known. MIT all the way.
I made a little map…
murm. Stuff. Can’t say
It’s unfiltered and GG probably knows about it already anyway: the running list started by @swissmiss: http://www.swiss-miss.com/2…
Yeah I wouldn’t mind hearing more about Theranos.
Shutting up now…..
What? Shutting me up?
no, shutting me, shana up. I know things about suff like theranos that I am not suppose to know
Lol. TELL ME.
Elizabeth Holmes is AMAZING as a role model:* http://fortune.com/2014/06/…
Omg omg omg omg I’m in love with this woman. Her mind, her direction, her confidence, her board, her vision. Did you read who’s on her board? I’m drooling. Except I couldn’t marry her because her meals are so boring but I could be her coach. :P. Thanks for this article- this is the most info I’ve seen on her in one place.
Info I know matters to a number of the companies on the list in a variety of different ways, and until some things are public, nope.Though I can share one interesting fact about Theranos: One of the reasons they work is a large large chunk of tests in general should not be done by hand and are way overpriced by experts in the field (as seen argued by experts in the field on facebok randomly one day). Most of the tech used is 70s-eqse. However, a large portion of cutting edge tests would still have to be done by hand, so it is questionable exactly how big the growth trajectory is. That is what drives most of their value – not really anything else
The missing link is about relatability.When a woman arrives at a website and sees content+comments that don’t look or feel relatable and relevant to her and her friends, their lives and their career successes…That website loses her as a reader.
Along those lines if your avatar and name indicated that you were a woman (vs. gender neutral with assumption you are a man which you are not as I know) AVC.com blog would benefit. Noting that there are very few woman, at least not in the closet (like you?) posting comments on AVC.com
Haha, so here’s the closet of women in tech. See how stylish the female spectrum of intelligence is? :*).The reason for my avatar is because I’m Chinese so Yin+Yang is my natural MO. I chose the colors for “blue-sky thinking with passionate heart of execution and purity of principles”.As for why I don’t go with a photo of how I look…So…Sheryl Sandberg remembers how as a child how everyone called her “bossy” (http://www.npr.org/sections….In my case, people couldn’t get past their stereotypes of how I looked.Well, pretty sweet little girls can also be seriously smart, have sharp senses of humor, play sports extremely competitively, win chess games, be better at Comp Sci and coding than the boys in school, be good artists and explain the Universe in several languages.@lisa_hickey:disqus — Yes, society can have the most paradoxical and non-sensical ideas about the purpose of women (“Look like arm candy” / “Be earth mother” / “Be girl-next-door” and non-competitive non-threats).I was 8 when I experienced my first instance of sexism; I beat a boy who was Regional Champion and 3 years older than me in a chess competition. His teacher was outraged: “How could you let a pretty little girl beat you?!”Erm..he didn’t LET me beat him. I beat him fair and square and was the better player. Simple as that.It was shocking because in my family no one ever gave me the memo that I couldn’t go forth, learn, play, make friends and do anything I wanted to because I’m a girl.In any case, from thereon I decided it didn’t matter what other people’s narrow-minded gender stereotypes are.The only thing which matters is that we’re open to learning, realizing our potential as human beings and paying it forward for the greater good.
In my case, people couldn’t get past their stereotypes of how I looked.To me at least if you were a chinese or asian woman you would rank higher in the pecking order (at first impression) than a non chinese woman all else equal. [1]Not only that but if you have a “handicap” (and let’s be clear certain men have handicaps as well and I’m not talking about skin color either I mean height, dress, voice and so on) [2] it just means you need to work harder and make sure that what comes out of your mouth makes sense and convinces the opposing side.[1] One of my customers in the 80’s was a black woman, Azie Taylor Morton [3] who had signed currency when she was treasury secretary. When I first met her all I saw was a black woman and this was the 80’s. So what do you think that I thought? But she definitely seemed to be different and when I saw her signature on a work order I thought “hmm I’ve seen that before”. Then I looked on some currency and there was the same signature! It was the same woman! (She had been doing some work for Dr. J the basketball player iirc). So yes I had a bias (how many black women did I meet at the time that had acheived anything? 0) but what she said and how she acted clued me in that she was different. (Dr. J I would notice right away, right?).[2] I met a salesman the other day who I had only spoken to over the phone. When I met him I was dressed in jeans and a t-shirt which is how I dress 99.9% of the time. He said “are you the guy that I spoke to over the phone???”. So if I had never spoken to him over the phone perhaps he would have felt superior at the first meeting (despite the piece of shit car that he drove up in by the way) but that doesn’t matter to me. I’d rather have that then have someone think I mean business just because I look the part and because I was tall (I’m not) or have a deep voice (don’t) and commanding presence (nope). In the end what you say is what matters and maybe I would imagine you might get pretty lazy (and then I will mow you over with your guard down) if you rely on the physical appearance things.[3] https://en.wikipedia.org/wi…
As a long-time female follower of Fred, I would have to agree with @Shalabh’s comment on this one. I also never want to be known as a “female entrepreneur” I want to be known as an “entrepreneur”.However, I appreciate @twaintwain:disqus point below about “relatability”. But I think it goes deeper than “those people Fred writes about don’t look like me therefore I don’t relate.” I think it is a combination of the following:There is a group of very smart, articulate people, mostly men, mostly regular commenters, who fill the comment section within 10 minutes of a post of Fred’s going up. Add onto that the data that Fred’s audience skews wealthy, and I would guess very well-educated. To a potential female reader, this could make it feel like a “boy’s club”—or even an “old boy’s network”. It’s what has historically been difficult for women to get into.Now—let me be clear—I don’t believe men are intentionally shutting women out of anything—especially not here. I’ve never once felt unwelcome, invalidated or not an engaged part of the group. And people have disagreed with me or called me out when I don’t have my facts straight—which is great. That is why I keep showing up. But I will say that throughout my life, I’ve had to make an active effort to include myself in what seemed to a lot of people like “boys networks”—once I even learned golf to do so. It just always took a lot of work, in ways that weren’t always intuitive to me.Also, because the focus here is on a combination of tech and investments—women (again historically) haven’t learned that language. The societal pressures on men are to be “financial providers”, the societal pressures on women are to look good and nurture their family. It’s all stupid, and any one individual can–of course—rise above those pressures and—regardless of gender, do both. And certainly society now says it’s “OK” for women to do anything they want and it’s starting to open up so men can feel good about doing anything they want to do as well. But the “pressure” to do so has still not really reversed itself.If you really want a higher female readership, I would not only look for “women to write about” but also more ways to get women who are doing really cool things to be a part of the community. What might that look like? Well, first, do you follow any women’s blogs? Could you quote those? Are things women doing a part of the mega-trends you are seeing? Are there women you ask for advice? No woman wants to be the “token women” (not at all saying that is what was implied.) But they want to be a deeper, highly relevant part of the conversation, and if other women see them I bet they would participate more.
Agree. I think a core part of this is being willing to a) do the work to bring in + welcome more voices and perspectives b) simultaneously point out that the importance of those voices is not simply due to one characteristic it is due to their varied experience.It’s a challenge I think about a lot – if we’re being honest there are a lot of people in the world who would rather be right than be good, the latter defined in the context of entrepreneurship as helping more people build, learn, and have access to capital and other resources.
If you have means and access you must promote others. How else to justify success, for crying out loud?
Yep, indeed. The hard part being when their idea of what works and what matters doesn’t line up with yours, takes some grace & being good to still do your part. Though, I will say that the “pulled up by my bootstraps” crowd sometimes implies that people who don’t get there aren’t trying hard enough, and that’s a complex kind of justification to deal with.
thank you
It won’t.
Believe it or not, when a woman shows up to a blog and sees 85 men and no women (or just 1 or 2) chatting in the comments, it takes a bit of … courage (based upon past experiences) … to join in. But, if the topic that day happens to be about a female-led startup, it makes the welcome sign a little brighter. Then hopefully she’ll stick around for more conversation.Diversity in the comments participants is a good thing to strive for, for all involved.
I think we picked up a few during the XX Combinator days. That was fun, even with the trolls.
*sigh*
I think that’s when I turned up…
That seems about right. And that was a very good day Anne Libby.
Aww.
One more Suggestion. I remember you once said USV doesnt invest in India because its too far. But look. India is at #4!
@fredwilson:disqus – have you run the numbers for the GG?
what about the important stuff? mets or yankees? knicks or nets? coke or pepsi?
mets, knicks, diet coke
and jets.
yessssssssss
Maybe some posts about women’s soccer can skew your blog’s demo a bit. I saw a clickbait headline from Inc. or Fortune or another business magazine about leadership lessons from the U.S. Womens National Team.
I didn’t watch the match, but a pal in the gym told me they had female models in mini skirts at the trophy presentation. WTF?
Think I fell asleep by that point, but bear in mind some of the players are attracted to women. Check out that gal from NJ’s goal from midfield though on YouTube. That was pretty cool.
That’s because everyone likes looking at attractive women. Have you not seen a magazine rack lately?
No. I don’t look at racks.
You have been a source of inspiration for some years now. Not only do I appreciate your commentary on whats happening in the tech and VC world, but I am also a regular reader of your tumblog. In fact you are the reason I have started blogging about music (www.shalabh7.tumblr.com) and sharing my thoughts on finance and tech. Thank you 🙂
excellent!
I started reading Fred’s blog way back when because of the music, tech, and NYC stuff, and then learned a lot about the VC business simply by hanging out. I didn’t come for the startups, but now I love that part, too.
same here
Came for the startups & VC, and came to love the rest. Fred was an influence in my developing a love for indie music — which still baffles my kids. It’s fun to keep them guessing.
You forget to include the all important “Dry Pasta” preference. My followers are at 50%. Yours?
Only “Dry Humor” around here.
I’d only expect such a starchy comment from you.
This is serious business. Don’t be so fusilli.
Wish there were a “groan” choice between “up” and “down”.
duly noted
Wow, this subthread is the whole enchilada.
What’s eating you today that you are so cereal?
Let’s see 🙂
Haha, that’s BRILLIANT!Does Twitter also split the metrics out between spaghetti and farfalle?
Paleo and vegetarian?
Spelt or durum?Full-bodied rigatoni in durum wheat semolina per me, grazie!Of course, my Italian friends and I are always at each other about how pasta’s a Chinese invention. They copied our noodles.Worst Chinese meal I ever had was in Rome. Instead of proper prawn Chinese dumplings they served some type of minced ravioli. Ugh!
best chinese meal outside of china?
* http://www.yelp.com/biz/lai…
Malaysia has excellent Chinese food. Also, in Kuala Lumpur, the food courts (and higher-end restaurants, but I’ve not been to many of those) have many other types of Asian (e.g. Vietnamese, Thai) and other cuisines’ dishes. Great fun to explore.
Closet smoker?
haha
Considering how they most likely compile those numbers and specifically how close they are, the above is practically meaningless. I guess all of the ad buyers just graduated from a college level course in media buying.So 50% of audience shows “dry pasta” but only 46% shows “pasta sauce”. Right. So 4% either eats the pasta dry or makes there own sauce. Right.I remember when Netflix (before you could define separate users) used to try to recommend movies to me based on what my wife or my kids would watch on the same account. They algorithm didn’t even have the smarts to figure out what was going on. They could have easily seen the time of day the movies were viewed and made some assumptions from that (afternoon vs. late night and so on..) So they wouldn’t recommend a kids movie at 11:00pm when most of the movies watched at that time were of an entirely different genre any human could have figured that one out.
the difference between a data scientist and a statistician is one ignores the noise in the data, the other actually reports it.Btw, I’m a little surprised that some folks are not a little creeped out by this level of data collection.
true that
Rich…Google wants to put nanobots INSIDE OUR BRAIN CELLS…”Ultimately these devices will be the size of blood cells, we’ll be able to send them inside our brain through the capillaries, and basically connect up brain to the cloud,” Kurzweil says. “But that’s a mid-2030’s scenario.”In Kurzweil’s vision, these advances don’t simply bring computers closer to our biological systems. Machines become more like us. “Your personality, your skills are contained in information in your neocortex, and it is information,” Kurzweil says. “These technologies will be a million times more powerful in 20 years and we will be able to manipulate the information inside your brain.”* http://www.marketplace.org/…Creepy or normal?
OH: Definition of a statistician: A person who has his feet in the fridge and his head in the oven, and says “On the average, I’m feeling quite comfortable.”
The Ramen Delta.
This is anecdata, and based on a small sample size (my own experience only), but I’ve found that software-generated recommendations in general are mostly crap.
Clocking 56% on the DP index here. Mostly due to several semolina tweets I made over the past few months, which caused it to gain traction on the Ice cream & Novelty crowd, which frankly, I will have none of.
well, Twitter needs to cater to the food advertisers 🙂
Just had a crazy idea. The way things are going, I wonder if at some point in the future, there will be in-food ads ………. :-)(I mean, like really in-the-food).If it ever happens, remember you heard it here first. (TM).
Laughing out loud! OMG!
because pasta is amazing
If you all of a sudden became only interested in cooking (or 80-90% of your content, I wonder how much weight that would affect everyone elses’ interest lists.
I’m happy to be keeping your female & international audience ticking along , even if both are in the minority . I enjoy reading your work. Thank you !
Thank you, Fred, for the accuracy and consistency of your message. And for posting so often!
Fred, can you share engagement numbers too? This was mostly demographics. Eg. metrics like tweet impressions, mentions, to tweets, etc.I mean you always preach about engagement, daily actives, etc.. That’s more significant that absolute users 🙂
attached are some high level engagement metrics for the past 28 days49 tweets1.26mm tweet impressions (roughly 26k per tweet)46k profile visits~1,900 @mentions
Thanks! 1.26mm tweet impressions (roughly 26k per tweet)- that’s huge.but you could tweet a little more often…If you back out the 28 daily posts that you re-tweet, that leaves less than 1 new tweet per day.
i don’t tweet out my posts most days. maybe once or twice a week. whenever i feel like the post has mass appeal.and i don’t tweet that often.most of my tweets are @replies and RTsi believe less is more on Twitter
it’s interesting to compare the 26K impressions per tweet vs. 50K readers (my guess?) per blog post.
The “right amount of tweets” is interesting. When I started using twitter, I used to hate when someone tweeted more than 4-5x per day. It felt overbearing. From the few friends I polled at the time, they felt the same way,Now, many of my favorite people to follow tweet way more often than 4-5x per hour. And many of the people I polled early on feel the same way now.Much like a Reese’s, there is now right way to do Twitter. Everyone finds the right amount to tweet. But I’d wonder how many others felt their twitter consumption preferences change over time?
The anti-@pmarca 😉
In many ways
So true … Twitter overuse is a thing … “whenever i feel like the post has mass appeal” is a good filter.
There are great comments each day (screenshot a fave comment so you could fit it all in) that would make a great tweet on its own if you were interested in tweeting a little more, add a couple words of commentary.i realize you probably have little need to do this but there are often huge nuggets here, not always spot on the topic either.
Sign me up as a relatively low net worth, android using international male. Every day.
yesssssssssss
Counting those s’s.
same except US
seems you’re on trend… “Compared with late 2013, the service [Twitter] has seen significant increases among a number of demographic groups: men, whites, those ages 65 and older, those who live in households with an annual household income of $50,000 or more, college graduates, and urbanites.”http://www.pewinternet.org/…
they made a movie about that cohort a while back http://www.imdb.com/title/t…
bahahah…
For some people it might be intimidating to read AVC. Many people are prohibited by their work, by FINRA or some other construct from commenting.Suppose I was a person that wasn’t wealthy and wanted to use the resources of this blog. Obvious ones are MBA Mondays(http://avc.com/2013/08/a-ta…. But, instead of concentrating on the content in the blog sometimes it’s better to peruse the comments to try and generate that spark that becomes the idea that becomes the company.
Many people are prohibited by their work, by FINRA or some other construct from commenting.I am wondering if in addition to a prohibition it’s a general corporate mindset that there is more to lose by saying something (see Trump) than there is to gain in an employees mind. Like lose their job or have something that they say be held against them at some point. One of my sisters for example is the exact opposite of the way that I am. She is a good corporate soldier who doesn’t have any interest and doesn’t want to stick her nose into anything that isn’t her business. Really has no curiosity. It is simply not what floats her boat. She has always worked well and risen in the corporation by being that way I would imagine (not something she discusses). She recently got a new job and didn’t even tell anyone in the family didn’t even want to talk about it. As a matter of fact I didn’t even know the last 3 jobs that she had.
100k people with net worth > $1M seems like a lot… where do these stats come from?
twitteri put a link to their analytics service in my postcheck it out
I think he meant how does twitter knows this information, no?(…as net worth is not something you can track with web/mobile traffic.)@andreyfedorov:disqus my guess is that twitter also has survey data associated with their registered users.
Exactly. Right there you can question some (but not all) of the other numbers. Some of this is self reported.No way 24% of twitter followers of Fred have 1m+ net worth. Defies common sense. As they say, “doesn’t pass the smell test”.
Think like a Bayesian
“Bayesian”I scream every time I hear thatword in a technology discussion.Bayesian is just the babytalk version of something muchbigger and really important.The grown up version from Loeve,Neveu, Breiman, Kolmogorov,Cinlar, Dynkin, Halmos, …,Shiryayev, etc. isconditioning, especiallysurrounding the Radon-Nikodymtheorem and central to Markovprocesses (past and futureconditionally independent giventhe present), martingales,sufficiency in statistics,Brownian motion and potentialtheory and its connections withmathematical finance, stochasticoptimal control, of course,regular conditionalprobabilities, non-linearfiltering, and much more.Once I took the Hahndecomposition, basically acorollary of the Radon-Nikodymtheorem, and wrote out arelatively general proof of theNeyman-Pearson result instatistical hypothesis testing.Really conditioning isthe main technique of makingbest use of information — e.g.,why it’s in stochastic optimalcontrol, mathematical finance,and sufficient statistics. It’sbig stuff. In the work of thenames I gave above, see a lotabout conditioning but nearlynever see Bayes.There are proofs of theRadon-Nikodym theorem in booksby Loeve, Neveu, Breiman, etc.The famous, and novel, proof byvon Neumann is in W. Rudin,Real and ComplexAnalysis.Some people in appliedstatistics use Bayesianin ways with only meagerconnection with mathematics.
Quite. 3 graphics to illustrate how Bayes isn’t Markov:(1.) Bayes.(2.) Markov on social networks.(3.) Markov and Viterbi on natural language.
useful
The above graphics are standard in mathematical AI.They’re not necessarily the tools I buy into completely — even if it’s what all the leading AI / data science researchers use (because they’re the only tools that currently exist).
Inhttp://avc.com/2015/07/4000…above, I just gave the basic definitions. You mentioned some areas for applications where some of the definitions might or might not hold.Of course the definitions are not all the same.
Also, there’s a difference between conditioning in Markov and conditional in Bayesian probability.Regardless, neither Markovian conditioning nor Bayesian conditionals can help the machines parse the subjunctive expressions inherent in our communications (text, speech, Natural Language).This is because in the subjunctive, simultaneous entangled “super-position” functions happen:(1.) Time — ok Markov can do past, present and future but only as a discrete variable rather than as continuum.(2.) Emotions — maths as a language tool isn’t enabled to deal well with this (yet).(3.) Situational context — where conversation happens (social network or ecommerce checkout?), who it’s between (social relationships), how many steps to action etc.There isn’t yet an adequate maths to deal with this. Just as there isn’t adequate maths to solve Einstein-Schrodinger’s equations on relativity and super-position of cat is dead AND alive.Dead = 0Alive = 1So how can 0 = 1 simultaneously?
It’s always bugged me, in the little probability that I’ve encountered, how there’s so much emphasis on what one can do with a fair coin, and so little on what one can do to determine how fair the coin is (or whether you need more coins).Emotions seem to me to fall on the latter side of this dichotomy – individual preferences are at least vaguely analogous to probability distributions (in commercial terms, “I’ll go for product X if I’m feeling upbeat, product Y if I’m feeling cheap, nothing at all if I’m depressed” sort of stuff).As for the discrete-versus-continuous-time issue, that seems a relatively straightforward issue (warning: possible mansplaining ahead?) – keep time discrete, but with really small time steps so that you can catch both the short-scale changes and the long-scale changes, and threshold boundaries so the long-scale changes only show up when they’re actually significant. Sort of like how neurons do it (which is, after all, the point). The problem on the latter is that it’s really hard to pin down when, or how quickly, the long-scale changes start: someone doesn’t get depressed over the course of a second, it’s over the course of weeks or months that one notices it in retrospect.
Except…emotions can’t be fitted into a Probability distribution. That’s the “Whale in the Room”.Add onto this that time, regardless of whether it’s discrete or continuous, has been assumed to be linear rather than quadratic (or other function even topographic). Linear meaning that 12:01 follows 12:00 and is before 12:02.Let’s suppose a person eats an ice-cream in the summer at time, t=0. They eat the same ice cream every week until it’s winter, {t+1, t+2, t+n… where n is the number of weeks after t=0}. The time they eat the ice-cream also varies. Sometimes, they eat it at 13:00 when the sun is high in the sky. Sometimes, they eat it at 18:00 as after dinner dessert.Therein are factorial effects of time on that ice-cream……..Which NO ONE has ever recorded or had the means to measure (yet).Time isn’t a linear arrow or a straight line axis as has been assumed. It’s quantum with wave-particle duality and superposition between the observer and the subject.At layman’s level…HUGE IMPLICATIONS for data science, statistics, probability and all that jazz.:*)
Going to nitpick/explore your choice of examples there – but your point about nonlinear time is a good one. The behavior I’d associate with quadratic time would be “flurry of activity when someone’s trying out something new, which tails off as they become familiar/bored with that activity”.Maybe that quadratic event interval isn’t what you meant by that, though. Your ice cream example I’d put down more as cyclical than quadratic – just with multiple factors determining which time the ice cream got eaten. Summer? Top half of one sine wave. Time of day? Another few sine waves, and noise, i.e.: functions we don’t know how to calculate, which I’m pretty sure is your ultimate point here. Supposing we’re trying to predict when they’ll next want ice cream, the problem in my mind boils down (possibly erroneously) to figuring out how many coins to flip and how often, which as we’ve both previously stated there doesn’t seem to be much established math for.Or, in other words, we more or less agree and think this is awesome stuff to be exploring, we’re just saying so in slightly different ways. 🙂
We are not communicating at all well.There is Bayes Rule: In probability, for events A, B, there is the definitionP(A|B) = P(A and B)/P(B)Then alsoP(B|A) = P(A and B)/P(A)= P(A|B)P(B)/P(A)Fine. No problem.P(A|B) is conditional probability.So, yes, Bayes rule is part of the beginnings of conditional probability.When we get out of the elementary stuff, we discover that given random variables X and Y, we can take the conditional expectation E[Y|X} which is a random variable, a function, say, f(X), of random variable X, and integrates like Y over all events in the sigma algebra generated by X. Indeed, we can be given a non-empty index set I and random variable X(i) for each i in I, let S be the sigma algebra generated by {X(i)|i in I}, and write E[Y|S] which, again, is a random variable that integrates like Y over all events in sigma algebra S. That we can do this is from the Radon-Nikodym theorem.That’s a start on the grown up version of conditioning.Suppose R is the set of real numbers and for each t in R we have random variable X(t). Then X is a stochastic process.Let U(t) be the sigma algebra generated by {X(s)|s < t} and V)t) be the sigma algebra generated by {X(s)|s > t}. Then X is a Markov process provided that for each t in R, the sigma algebras U(t) and V(t) are conditionally independent given the sigma algebra generated by X(t).Yes, this definition holds in continuous time t.Markov processes can be in discrete time or continuous time and have discrete or continuous or essentially arbitrary state spaces. No doubt more generality is possible.Those are the basic definitions.To fill in an ocean of details, there are books by Halmos, Doob, Loeve, Breiman, Neveu, Chung, Cinlar, Gihman and Skorohod, Dynkin, Karatzas and Shreve, Blumenthal and Getoor, and much more.
Ok, so I had this epiphany: Probability was invented to measure the STOCHASTICITY of dice but not its subjectivity. Unlike us, dice have no emotions, values, culture, language, experiences etc.I know different Probabilistic, matrix and Hilbert space methods have been applied in AI, including Google’s Word2Vec (and Sentence2Vec) which fuses Minsky’s symbolic and connectionist models — please see images.In Feb 2015 in SF, I went up to Greg Corrado of Google, one of the inventors of Word2Vec & Sentence2Vec, and asked him, “How does your system deal with subjunctive tenses which is a form of conditional probability. Can it do conditional probability?”[The colleague in question was Quoc Le, a leading AI researcher who specializes in Natural Language Processing.]Greg Corrado: “Can you give me an example of that?”Twain: “So in your colleague’s example he had ‘He gave her a pen in the garden’, ‘In the garden she got a pen from him’ etc. With subjunctive tense the sentence would be ‘She was so happy to get a pen from him in the garden as it was sunny.”Greg Corrado: “No, we can’t do conditional probability with our model.”So…we may see the problem set as this: the dependent variable is the pen. The independent variables are her emotional state and his behavior (1 = gives a pen, 0 = doesn’t give a pen). The conditional is the weather condition (0 = not sunny, 1 = sunny).Except it’s not as straightforward as that.Probability and Markov are about stochasticity.Her emotional state, before and after receiving the pen as the weather event happens, is about subjectivity.
I gave a good definition of a stochastic process. The standard example is the S&P average on the NYSE. Other examples include Brownian motion, the height of water on a pier due to ocean waves, nearly any electro-magnetic signal from space, and the clicks on a Geiger counter.I gave the definition of a Markov process. Markov is not a synonym for random or stochastic.Brownian motion and a Poisson process, e.g., with some simplifying assumptions, clicks on a Geiger counter, arrivals of search requests at Google, the time of the next Tweet, are all examples of Markov processes. It turns out, a deterministic process is Markov. Probability was invented to measure the STOCHASTICITY of dice but not its subjectivity. The early days of probability were for calculating odds in gambling. The results were terrific for gambling and much better for much of science. The outcome of rolling dice is regarded as random and not stochastic.I’ve given an overwhelmingly strong list of many of the most serious authors in probability and stochastic processes: I doubt that the word stochasticity appears in any of their writings.For Probability and Markov are about stochasticity. I would recommend rewriting that as Probability is about randomness. So, drop the mention of Markov and use randomness instead of stochasticity.For “How does your system deal with subjunctive tenses which is a form of conditional probability. a connection between “subjective tenses” and “conditional probability” is at best vague.In particular, I gave the definition of conditional probability: For events A, B, the conditional probability of A given B isP(A|B) = P(A and B)/P(B)Nowhere in this definition did I mention tenses in language, and, from all the natural language I’ve studied, I’ve never seen tenses described as “a form of conditional probability”. Indeed, how to take a discussion of tenses in language and get toP(A|B) = P(A and B)/P(B)needs a flight of fantasy.Yes, one could take, say, “If I can fix the loose carburetor mounting on the lawn mower, then I can finish mowing the back yard.”So, yes, might define event A as “I finish mowing the back yard” and event B as “I fix the loose carburetor mounting on the lawn mower”. Then one could consider the probability of A, P(A), and that of B, P(B). Then the conditional probability I finish mowing the back yard is P(A|B).A and B are events, not variables, independent, dependent, or otherwise.Yes, from event A can construct a random variable, the indicator random variable of A which takes on value 1 on trials where event A is true and 0 otherwise.Still getting that conditional probability P(A|B) out of grass mowing and lawn mower repair is a long way from anything in English grammar, subjunctive or conditional moods, etc.In particular, for your Can it do conditional probability? I can’t get any meaning out of that at all, in the context of attempts at natural language processing in artificial intelligence or anything else.For Her emotional state, before and after receiving the pen as the weather event happens, is about subjectivity.” That an “emotional state” is subjective seems not very important for a discussion of probability: If could get some data on “emotional state”, then, as usual in applications, might be able to apply probability, stochastic processes (as the state varied over time), or statistics, e.g., to predict emotional state from some independent variables.Or, maybe let event A be the person is euphoric and event B is that they took too much Prozac. Then maybe P(A|B) = 1. Or event A is the person is hungry and event B is that they have not eaten in two days. Then P(A|B) = 1 or nearly so. How to know? For each of many people, ask them when they ate last and if they were hungry. Then estimate P(A|B) and discover that it is close to 1.There is a lot of poor use of terminology and a lot of misunderstandings in your post: Elementary probability theory is usually nowhere nearly this difficult to learn or apply.I don’t have a good elementary reference for you: I picked up the elementary stuff so quickly I never really even studied it. My first serious study was in terms of measure theory and from J. Neveu, Mathematical Foundations of the Calculus of Probability, an especially elegant treatment, and a star student of E. Cinlar at Princeton. It was the best course I ever had in school. Easier to read, nearly as advanced, still a course in graduate probability, but much less elegant is Breiman, Probability, published by SIAM. Breiman may also have an elementary text; as good as Breiman is, just go for the graduate level text.Minimal prerequisites include, say, Rudin, Principles of Mathematical Analysis and Royden, Real Analysis although more theorem-proof style math of wide variety would be helpful from abstract algebra, linear algebra, applied advanced calculus, axiomatic set theory, point-set topology, etc. Also helpful could be a good course in elementary statistics — please, a good course, not independent reading. Naw, maybe delay statistics until you’ve got a solid background in graduate probability — elementary statistics is usually taught in such an imprecise way that it is just awash in nearly irresistible opportunities for serious misunderstandings.To learn such math, somewhere, say, in abstract algebra, take a good math course that is all about theorems and proofs and where the prof is a good mathematician and will carefully read and correct your work.In the end, year by year, mathematicians must be over 90% self-taught, but to be able to do that just must be able to check with nearly perfect reliability own proofs and related work for correctness. Just crucial. To learn how to do this, need at least one good theorem proving course from a good prof, as I outlined. Else the guaranteed path is off the road and lost in an endless swamp.Next, for study on your own, read slowly and carefully to the next theorem. Several places it may say “clearly” — that may take up to an hour! Try for a minute or so to guess the next theorem. Then read the theorem, close the book, and try for, say, up to at least an hour, but not for more than a day, to prove it. Then study the proof in the book. Close the book again and write out that proof. Read to the next theorem or the exercises. Do a good fraction of the more difficult exercises. Try to think about the material and get a more broad understanding with, perhaps, some good additional details. If get stuck, get an alternative treatment from another text. If you have a prof, ask them. Can also ask on the Internet. Work slowly and very carefully. Then you will learn this stuff.One more warning: Math has had two problems for students: (1) It is generally regarded as by far the most difficult college major. (2) The field and teaching, even when they cover just terrific material, rarely make good connections with applications. So, math has become an unpopular major.But, now with the rise of so much in computing, math has become valuable. Then the computer science community has been trying to teach some of math. Warning: Nearly none of the profs in computer science have good backgrounds in math, and the whole computer science community is struggling terribly with math, even with a lot of elementary material. Net, computer science is no place to go for math and is no substitute for math.With the math I’ve outlined, we’re talking top, center crown jewels of civilization here, in places cleverness, inventiveness, elegance, beauty, and power beyond belief. Maybe you will/will not like and/or apply such material; the choice is yours.For my startup, I’ve had my original math clean for a long time and since then have been mud wrestling with bad computer documentation and doing just routine things. I’m eager to get this startup done and get back to mathematics and mathematical physics.
I have a maths degree in which I got 99% in Probability & Statistics and summa cum laude for Econometrics project and later wrote about Black-Scholes and derivatives for the top risk management journal in the world, so know about stochastic and dynamic-based applications in finance.Also studied Physics so know Brownian and latency.It’s never been about whether Probability & Statistics & other maths is robust for existing examples like grass mowing and lawn mower repair.You wrote: “Still getting that conditional probability P(A|B) out of grass mowing and lawn mower repair is a long way from anything in English grammar, subjunctive or conditional moods, etc.”THAT is the point.The question is not whether maths can handle metaphysical, random, stochastic, discrete, continuous events with dynamic variables…The question is whether maths as a language can handle grammar, subjunctive, conditional moods, time factorials etc!!!
Re what you wrote, “The outcome of rolling dice is regarded as random and not stochastic”, here’s Merriam-Webster:stochasticadjective sto·chas·tic stə-ˈkas-tik, stō-Definition of STOCHASTIC1: random; specifically : involving a random variable 2: involving chance or probability : probabilistic Bayes is indeed not Markov.However, to say that they aren’t both probabilistic and stochastic (random) would be to say that Merriam-Webster and how we’ve defined them is wrong.
Here Webster’s is flatly wrong.Definitions and Italics:In well written math, and in any good technical writing, except for preface and overview material, we are careful never to use a term before it is defined. When we define a term, we type the term in italics. Otherwise we use italics for a word used with a meaning different from its usual dictionary meaning.Math Terminology:We need some careful descriptions of terminology; in an effort to be brief, don’t laugh, I tried, and even omitted some math I typed into TeX and was ready to convert to a PNG file an upload as an image.It’s an old story in math:Variable:”For mass m moving at velocity v, the momentum is mv.” So, here v is a variable. So, what the heck is this variable thingy, verbiage, terminology?Here is a translation that works in nearly all reasonably well written math and applied math: “Think of a number. Call it v.”While that is a good start, it is common for usage to make some vague extensions, but in well written math, there should never be, and really rarely is, any doubt about the meaning.Random:In probability, at least in the most serious work, increasingly so since A. Kolmogorov’s 1933 paper Grundbegriffe der Wahrscheinlichkeitrechnung, we try not to define random. Intuitively, roughly random means unpredictable — but looked carefully this is not good enough.But probability since Kolmogorov’s paper is crystal clear and rock solid, no doubt at all, about just what the heck a random variable is. I’ve tried hard to omit the definition, but here goes.Preface: Net, you likely won’t like the definition, but, net, you will get pushed irresistibly into this definition anyway, like it or not. Really, there is not much choice.Power Sets: Given a set A, we let 2^A denote the set of all subsets of A. Then a standard result in set theory is that the elements of A cannot be put into 1-1 correspondence with the elements of 2^A. For some terminology, 2^A is called the power set of A.The set of natural numbers N = {1, 2, … } is said to be countably infinite. So is any set that can be put into 1-1 correspondence with N. Any subset of a countably infinite set is countable.A set that is not countable but has a countably infinite subset is uncountably infinite.There are some uncountably infinite sets: E.g., from what we said above about power sets tells us that 2^N is uncountably infinite. In addition, the set of real numbers R is uncountably infinite.We are getting close to the continuum hypothesis and don’t need to discuss that so don’t.Given a non-empty set, X, call it a space. Let M be a collection of subsets of X so that X is in M (that is, X is an element of M) and whenever A is in M, A’, the relative complement of A, that is, X – A, is also in M. For B(i) in M, i = 1, 2, … the intersection of the B(i) is in M. So, M is non-empty, has X in M, has the empty set in M, and is closed under countable intersections and countable unions. Then M is a sigma algebra on X.The sigma used here is supposed to suggest countable as in countable intersections and unions. However it is a standard exercise to show that there are no countably infinite sigma algebras.It is important that we do not ask that a sigma algebra be closed under uncountably infinite unions and intersections. Broadly, in probability and stochastic processes, the difference between countably infinite and uncountably infinite keeps being important.Then the pair (X, M) is a measurable space.Suppose K and M are sigma algebras on X. Then, with an easy proof, the set theory intersection of K and M is also a sigma algebra on, X.Suppose Q is a non-empty set of subsets of X. Then by taking intersections of sigma algebras on X we can show that there is a unique smallest sigma algebra S on X such that Q is a subset of S. Then S is the sigma algebra on X generated by Q.Suppose for measurable spaces (X, M) and (Y, S) we have a function f: X –> Y. Then f is said to be measurable provided for each A in S we have that f(A)^(-1) is in M.Then the sigma algebra on X generated by f is{f(A)^(-1) | A is in M }This construction plays a crucial role in the more general definitions of independence and conditioning, especially in stochastic processes.Suppose for measurable space (X, M) we have a function m: M –> [0,∞], that is, to each set in M, m assigns a non-negative number or positive infinity ∞.Suppose for disjoint A(i) in M and i in non-empty countable I, the sum of m(A(i)) is the same as m( union A(i) ), that is, m is countably additive. Then m is a measure on measurable space (X, M) and the triple (X, M, m) is a measure space.Let R denote the set of real numbers. Let Q denote the set of all open intervals, e.g., (a,b) a subset of R. Then the set B of Borel subsets of R is the sigma algebra on R generated by the open sets Q.We can show that there is a measure m on the measurable space (R, B) so that for each open interval A = (a,b) we have m(A) = b – a, that is, the ordinary length of A.Probability SpaceWe start with a non-empty set of trials Ω.On the set of trials Ω we have a sigma algebra F and, thus, measurable space (Ω, F).On measurable space space (Ω, F) we have a measure P so that P(Ω) = 1. Then P is a probability measure or just a probability, and the triple (Ω, F, P) is a probability space.Then for measurable space (Y, S), measurable X: Ω –> Y is a random variable.Now we know what a random variable is. In essentially all serious current or recent work in probability, this is the only use of the word random, and we give that word no more meaning than we have so far here.A random variable taking values in R is a real random variable, and in both theory and practice that is the most common case. So, here we have probability space (Ω, F, P), measure space (R, B, m), and measurable X: Ω –> R.That’s what a random variable is and is also as close as we come to saying what we mean by random.Stochastic:Suppose for t in R, X(t) is a real random variable. Then X is a stochastic process.Intuitively stochastic means varying randomly over time, but for the mathematics our only use of stochastic is in stochastic process as here. We give no further definition of stochastic. Our use of stochastic is as an adjective and used only in stochastic process. We have no extensions of stochastic to other parts of speech.Submit all arguments to any of the top 20 people in stochastic processes of the last 80 years or so.For Bayes is indeed not Markov. that makes no sense, does not even parse as English.In probability, both words Bayes and Markov are adjectives. So, the word Bayes cannot be the subject of a sentence. Neither can Markov.We may say Bayes theorem or Markov process, but it would be absurd to suggest that a theorem is the same as a process. That would be like saying (1) here is a cool milk shake and (2) there is a red car, but cool is not the same as red.It may be that, in some areas trying to apply probability, Bayes and Markov are used as nouns as names of means of analysis. If so, then that is sloppy writing.There is a sloppy way to proceed in applications of math: Take some math assumptions, some theorems that use those assumptions as hypotheses, and the conclusions of the theorems as analysis techniques and use the techniques in practice, if only as heuristics, without attempting to verify that the assumptions hold. A lot of work in applied statistics in practice is an example.It may be that, in parts of work in computer based natural language processing, analysis, and understanding, there have been some techniques used that depend on Bayes rule or Markov processes. Then one of these techniques is called Bayes and the other, Markov. Now Bayes and Markov have become nouns as names of analysis techniques. As some English might say, really bad show. Really worse show: Using the word stochastic except in stochastic process. Even worse, using a modification of the word stochastic as a noun. People shouldn’t do that.
Do you speak French, Spanish, Italian or any of those languages that have subjunctive tenses?Ok here are 2 graphics to provide context:(1.) English tenses — this is what all the Natural Language classifiers built by Stanford, Google, IBM Watson et al are based on wrt grammar.They follow on from Noam Chomsky’s structures for syntactic grammar circa 1957.(2.) French tenses — pls see columns on the left on ‘Imperfect’ and ‘Imperfect Conditional’. These are the subjunctive tenses.So not a “flight of fantasy” but a very real practical problem for Mathematics.The question, again, is: “Can conditional probability be applied to the subjunctive tense? If not, why not? What other mathematical invention needs to happen for the machines to be able to parse subjunctive tenses — if probability can’t cut it?”This is VITAL for machine language translation and also the machines to actually understand the meaning in our Natural Language when we type / say / record anything online.So…looking to your considerable mathematical knowhow to answer this!Thanks! :*).
Incidentally, as well as acquiring maths as a degree (and language) I also studied French to degree-level.I have a nice certificate from Paris Chamber of Commerce that says my level of French means I studied balance sheets and business plans in French.My paper was on ‘Les pièges cachés de valeur des accords sino -français’ (The hidden value traps of Sino-French agreements).Whilst working through Maths’ adequacy as a language for modeling human and machine intelligence, my natural language skills have been most helpful.
Do you speak French, Spanish, Italian or any of those languages that have subjunctive tenses? Maybe not: For French, Dad was good at it, read Les_Misérables in the original French. My brother was good at it — took two years of it in high school and actually learned it. My wife was super-good at it, like she was at everything in academics.In high school, I was horrible at French: The teacher started off with “inaspirate H”, and I lost her there and each day just fell farther behind.Eventually she kept talking about plooper perfect or some such, and I couldn’t figure out what could be perfect about French poop.At one point, the teacher required everyone to recite from memory the words to La Marseillaise. That was easy, and I had enough musical talent to start to sing it. So, I gave my required performance to her after school one day, and she cried.But there was no way I could learn French from her. I’m sure that now I could learn some French quickly and easily on my own, but, from her, then, no way. High school math? Great fun; mostly sleep in class; ignore the teacher; study the book; work enough of the hardest exercises to be sure I could work them all; be the top student in the class or nearly so; love the material — piece of cake.The class was about 80% girls, and some of them were really pretty!Since I’d not been able to learn French in high school, in college I tried German. I happened to have by far the best teacher of anything I ever had (not the best course or material but the best teacher). He had two classes, at the same time, so gave us each only half a class. I had him for only one semester. So, in half time, for one semester, he taught me enough German to get through two years of college German.How? The French teacher taught writing, reading, and maybe speaking, in that order. The German teacher taught reading, speaking, and some writing, in that order. For me, HUGE difference. Also the French teacher wanted to teach words. The German teacher taught mostly phrases which are much easier and better to learn.For the speaking, did some language lab work with a native German woman with a really good German accent. Later a German exchange student said that my accent was good enough to let me fool Germans into thinking I was native German. Actually, German is relatively easy to pronounce for English speakers, so just learn from a native German and do well.Later in grad school, I tried to take a course in differential geometry from a Czech guy who’d written a book translated into German by some pretentious German academic. His differential geometry was at the level of freshman calculus, but the German in his book was difficult beyond belief: I struggled with the words one at a time. I asked a German math student, and he said that the German was in some archaic style too difficult for him, also.Then I didn’t know what to do: I should have gotten a decent book, in English, of which there are several, on differential geometry, differential forms, and exterior algebra with applications to mathematical physics and continuum mechanics and just dug in.For my Ph.D., near the end, my major prof told me to go to the library, get a math paper in German, and translate it. I did that: I got a paper in a subject I knew well, brushed up on my German one evening, and translated the paper the next afternoon. Easy.To grade the result, my prof gave my translation to a very bright fellow student, later got tenure at Princeton. In ugrad school he’d been a double major in math and German and had studied for a year in Germany. He liked Bratwurst und Bier. He graded my translation, found it all okay except really stuck me for my translation of one word. My translation was the one in Cassell’s Dictionary of English and German, but my fellow student knew still better! My prof gave me the needed pass on my foreign language requirement. All from half time in one semester from one good foreign language teacher. Good teacher. With what I learned from him about learning a foreign language, I could learn French also. Still wouldn’t understand what plooper perfect was. “Can conditional probability be applied to the subjunctive tense? If not, why not? What other mathematical invention needs to happen for the machines to be able to parse subjunctive tenses — if probability can’t cut it?” Now, finally, we are, maybe, beginning to get somewhere.Still, I have to mostly just set aside your Can conditional probability be applied to the subjunctive tense? This question makes me want to stand and scream in outrage loudly enough to blow down all the houses and trees for a radius of 20 miles, and that’s worse than most nukes. Can conditional probability be applied to the subjunctive tense? “Applied” in WHAT sense to do WHAT for WHAT part of WHAT for the “subjective tense”?Yes, aspirin “can be applied” to cure a headache. But it’s not even a question to ask of probability, or Bayes theorem, or a Markov process assumption, can be applied to the subjective tense.Without being much more clear on at least these four cases of WHAT, we don’t have anything, not an answer, not even a question.Yes, in some language grammars there are meanings for subjective and conditional, and there is conditional probability, but those facts alone are a very long way from applying conditional probability to computer based natural language understanding.The first cut connection I could see had to do with fixing a lawn mower and mowing the back yard, and that was not progress.I’m not much on grammar and am less good at linguistics. Reasons: I wanted to study material that actually made good sense and would be useful in my career, e.g., to make money, the green kind.I’ve tried to ignore efforts at computer based natural language understanding. Reasons: The computer people are struggling to do as well as a four year old can do, in the case of girls, likely 3 years old, in the case of a bright girl, maybe 2 years old. Bright girls are good with language beyond belief. So, the field looks too difficult. And for making money it looks like a research problem looking for a solution where that solution would still be looking for a good real problem.Another reason: My guess is that natural language understand can’t be separated from understanding, say, real artificial intelligence that is actually intelligent. I know; I know; I know; it’s all just around the corner, and has been since, what was it, Vannevar Bush and Perceptrons or since the early IBM computers touted as gigantic electronic human brains. That “corner” is where, somewhere on the dark side of a moon of a planet of a star somewhere in Andromeda? My hype, BS, and nonsense detectors are sounding loud and clear.For a solution, I would try to apply the college joke “ontogeny recapitulates phylogeny”. That is, I would try to have a computer learn by copying what it appears human children do. My guess is that early on this approach would appear to work well but then would soon encounter the question of what the heck are the ideas used in the human brain to store, retrieve, and process what it learned and the answer there would be close to real intelligence. I suspect that there the project would get stuck-o.For what Google is doing in natural language understanding, here’s my first-cut guess: Google likes to take advantage of their ability to use simple, empirical, brute force techniques. For something like natural language understanding, they have a lot of data, that is, that they got from crawling the Internet. They have a lot of words.So, for understanding, for each word, phrase, sentence they want to transform it into a canonical form so that, say, each sentence with essentially the same meaning gets translated into the same canonical form. Then for their understanding, they want to start with just the canonical forms they have constructed.Well, in this work, they can ask, “for sentence A1 and canonical form C1, from the details of both, what is the probability that the meanings are the same.”?In asking this question, maybe they want to ask the question, “Given the canonical forms of the five previous sentences, what is the conditional probability that sentence A1 and canonical form C1 have the same meaning”.Maybe they want to take a document and regard it as a sequence of sentences. So, for some positive integer n and i = 1, 2, …, n, A(i) is a sentence-valued random variable. So, they have a discrete time, sentence-valued stochastic process. Then they might want to make an assumption something like a Markov assumption that the meaning of sentence i is conditionally independent of the meaning of sentences i – k for k = 6, 7, …, given sentences i – j, j = 1, 2, …, 5.So, this assumption says that in trying to understand sentence i, need look only at the meanings of the previous five sentences.Okay, they might do some such thing. Okay, it’s an application of probability and conditional probability. I doubt that this application will make much progress in computer based natural language understanding, but Google has a lot of sentences, computers, people, and money, so, why not?Can start with really good flour, chocolate, sugar, eggs, cream, cherries, and Kirschwasser and make a really good cake or make a really big mess.Can start with some really good probability theory and do some really good science, engineering, whatever or can make a really big mess.In both cases, the inputs are fine; the quality of the results depend on how the inputs are used.For the natural language understanding, they need some good ideas — I doubt that they have ideas that are nearly good enough.I had some good tools to fix my lawn mower. And I did fix it. But also I had to have some good enough ideas — I had some good tools, and at least some tools were necessary, but the ideas were much more important.Can’t hope to make progress in natural language understanding simply by making an application of probability, Bayes rule, the Radon-Nikodym theorem, stochastic processes, Markov processes, martingales, etc. Instead, with these tools, also need some good ideas.Can’t ask if a box end wrench can fix my lawn mower: Not by itself, not without some good ideas. Can’t ask if something in math can have computers understand natural language: Not by itself, not without some good ideas.Can ask if an aspirin, by itself or with just some water, is good for a headache — likely it is. But, it makes no sense to ask if a Markov process assumption, or anything in math, by itself, will be effective in computer based natural language understanding — not by itself.
Re Markov, it’s widely applied in Natural Language processing.One of the things we’ve assumed about time, regardless of whether it’s discrete or continuous, is that it has no negative or positive force.Yet getting an ice cream in summer is very different from getting an ice cream in winter.
When Twitter starts tracking my self worth, then you’ll know the company is looking and moving forward.
I was going to say that, too. 100,000 millionaires reading one blog. VERY interesting, if possible.
Correction, I should have said 100,000 millionaires following one twitter user.
Reading and following on Twitter are apples and oranges.
Great numbers. I may be proven wrong tomorrow when you post the AVC numbers but I will guess that the Female % here on AVC will be higher than on twitter.
For AVC I’d like to see the goegraphic spread within the US and how it matches up with what are thought to be the growing tech centers in the US beyond west and east coast cities.Separately, i find many life lessons beneath the discussion of tech and finance that i frequently forward to my family. Thanks for helping with dinner conversation for teenagers.
Maybe it’s just me but the demographic information feels highly dubious/inaccurate. Especially when paired with the addendums like “Values based on 8.6% match rate from Twitter partners”, which I really don’t understand, but it doesn’t sound good.Apparently 56% of my followers purchase “ice cream & novelties”. I cringe thinking about the decisions actuall marketers/brands are making with this information.
actual marketers/brands make *many* decisions based on a lot less every day…it’s still way more alchemy than anyone likes to admit.
This is true. I am a strong proponent of seasoned marketers making gut decisions. But these twittalytics are providing the illusion of data to ‘data-driven’ marketers whos guts are not particularly honed.
Seems like every gut decision that a seasoned marketer makes still has to be backed up by fluffalytics or persuadalytics, for somebody, somewhere! And don’t interns make the best creative campaigns anyway? 😉
it takes a lot of training to understand whats going on underneath. most gut people are not great at it either…
Ogilvy (or some other famous person in advertising):”50% of advertising works. Only, we don’t know which 50%.”But his book Ogilvy on Advertising is a classic and a good read.I’ve only read a handful of marketing / advertising books (more of the former than the latter), but this is one I liked.
classic and stands the test of time well (so far).
John Wannamaker. He had a department store in NYC
I had come across his name earlier but did not much know about him. After you mentioned him I looked it up and saw the Wikipedia article about him. Interesting life story. There are many such American entrepreneurs’s stories of the last 2 centuries or so, and many of the make for good reading. (Same for other countries, of course.) I’ve read some. It would be great if there was some sort of list of such people though, otherwise it’s more by chance that one gets to know of them and only then can read about them.
Wana, though, says Wikipedia.
So true….
Interesting…i ran mine and 19 percent keep kosher…and 38 percent use ATT
24 percent of you audience is worth more than 1 million. I hope you dont mind if I hang out here and comment and raise capital.
Entrepreneurs with paper wealthIf you own 75% of business with a $2mm valuation you are a millionaire Until you aren’t
Im a paper trader so its perfect….
oh, yup. we’re hanging out
Someone gave me a dollar to buy 1 share in my company. I have 1000000000 shares. So we hanging out?
basically, yes
Great!
Bots like to pretend they are millionaires.
and female. Twitter is so skewed to male, I mentally just assume female follower = spam.[somewhat grinchy edit: Twitter’s analytics are not believable. I’ve seen a lot of head-scratchers, and not just in self-reported demographic data. Hard to sell ads if the analytics are wrong…Facebook and Google various problems but seem in a position to have a much better grip on their demographics and psychographics.]
“I mentally just assume female follower = spam.”So much dammit. (Not your fault, but dammit!)
hey
If what I’ve read is right, anywhere from 120,000 to 200,000 of Fred’s Twitter followers are bots. Unless he’s been amazingly diligent about blocking them.
And 99% of the ones with attractive female avatars lol. The internet hasn’t changed that much since AOL
I used to wonder why I had so many half-nekked women following me on Twitter.(mispelling intentional — pronounced neck-kid)
:/
Yup. Because who have heard of a poor bot
What would be useful is the ability the follow “pasta lovers” not knowing which of my followers love pasta.
Well I am certainly contributing to what diversity might exist in the wealth section, but I really wish I could find a different way to contribute.
Someday, Matt. And you might even be one of those “overwhelmingly wealthy” men (which is how I first read it).
wow, 400k… that’s amazing. you must feel really, really proud.
With data on all or most of thosevariables, Twitter should be able to dosome darned good ad targeting.I will resist writing out some of the mathfor how to do that! more female audienceYes! E.g.,http://emea.lum.dolimg.com/…”Now, girls, you didn’t miss that the AVCaudience has a lot of wealthy men? Andyou do remember that ‘A man being rich islike a girl being pretty.’? So, …,girls, you do know how to use a computer,post, with pictures, right?”Guys, there’s more to life thantechnology, startups, finance, and money.
Ah, well, Twitter doesn’t have the advantage of a female COO like Sheryl Sandberg to make sure the ad targeting understands female psychology:* http://www.adweek.com/news/…Twitter’s marketing is under Anthony Noto, a banker by background.
Sorry, my view is that to make sure the ad targeting understands female psychology and the idea of that article in AdWeek with the URL you gave are very badly wrong, wrong as in wastes money, for Sandberg and people doing ad targeting.With that AdWeek, etc., stuff, you just pushed me over the edge; I will respond:Ad Targeting 101The main idea of ad targeting is to get sales or, in case we can’t so easily measure sales, at least clicks.So, to illustrate what is wrong with the URL on Sandberg, etc.:We pick an ad want to study.As part of the study, to collect data, we run the ad and collect data on the users and the responses. Then we build a model that predicts the responses from the data.There are many ways to build such a model: The old standard was regression analysis, and there are several ways, some with fewer assumptions than others, to justify the model.The model building would go essentially the same if the users were cats, dogs, birds, fish, lions, tigers, all men, all women, or both men and women.Point: So, sure, if our users are people and include both genders, then to make that model more accurate, some of the data we collect should be on gender. Sure. No doubt.This point alone should be enough to accomplish for all the business purposes of ad targeting everything Sandberg and AdWeek have in mind, including female psychology, emotions, behavior, propensity to gossip, form groups with other females, and go for girl’s night out, suddenly just before leaving for a party to conclude that a new dress makes her look fat, accumulate a surprisingly large collection of shoes, easily become bored, resent housekeeping, like chick flicks and romance novels, eat chocolate, buy the latest fashions, be especially afraid of the unknown, do gold digging and social climbing, manipulate men, prefer the humanities to the STEM fields, like candle-lit dinners, pay much more attention to people than to things, to be much better than men at communicating with facial expressions and tone of voice, etc. as in Girls 101 for Dummies — Boys.Note: Quite generally, from an easy proof, if have enough data, then by far the best such predictive model — linear, nonlinear, machine learning, artificial intelligence, neural networks, or anything else now or anytime in the future — is just cross tabulation, including for everything relevant about gender.The AdWeek article? Click bait for women; pander to, patronize, and manipulate women and get ad revenue.Note: Since lot of money is spent on ads, better ad targeting can be worth a lot of money. Money is a quantity, a number; in ad targeting we want to maximize that number. So, we take in data, manipulate it, and conclude how to target ads. The manipulations are necessarily mathematically something, understood or not, powerful or not, valuable or not. For more techniques of targeting that are better understood, powerful, and valuable, by far the best approach is mathematics, some of which is not trivial.E.g., with a good statistical model for each candidate ad, given data on a user, evaluate the probability of a click or sale via each of the models and pick the ad that gives the best prediction. Could make money doing that.
Are your commentsthis wide on purpose?It makes them veryhard to read and annoying.
I try to position end of line locations so that Disqus and/or a Web browser will not add more, but that goal is not so easy (A) because of markup for block quotes, italics, and bold fonts and (B) because the multi-line text box for the input tends to have narrow margins and, thus, add end of lines of its own unless I keep my post line lengths under about 53 characters.But I can just post each paragraph as a single line and let Disqus and/or a Web browser insert the end of line breaks. I just did that for my post you responded to. Maybe you find that result easier to read.Actually, I like line lengths of only about 50 characters. As I recall, traditionally newspaper columns were only about 40 characters wide.
Two graphics:(1.) Neuroscience of advertising.(2.) Female $$$ factors — one of my slides.
I see nothing wrong in your slides.Suppose we have some good ad targeting and suppose some one person get’s it for women and comes out with an ad that is based on and takes good advantage of what is in your slides.Then, presto, bingo, the ad targeting should show for that ad one heck of a shot of additional revenue or at least click through rate, and that one ad author should get a great office on whatever the street in Manhattan is the great place for ad agencies and get paid the standard fraction of ads for trillions of dollars in sales, billions in ad revenue, etc. There’s a lot of motivation for some one ad writer to get it.With good ad targeting, all it takes is just some one person who get’s it.If so far there is no one who get’s it, then maybe there is a severe challenge here?We were talking about AdWeek: For ads that make money, the main measure is sales or, if that data is not available, just clicks. Then the main means of making decisions about what ads to run, of those that are available, is just ad targeting as I outlined.Then, for building such ad targeting models, as I mentioned, the applied mathematics, statistics, etc. works essentially the same for predicting the responses of cats, dogs, etc. Of course, should have some data for gender and, for dogs, may want some data on breed. Of course, also want age, weight, etc. if can get them.In this model building, if look at how the math works, don’t really have to understand the dogs, cats, men, women, etc. and, instead, if have a variable that just might be useful, and have plenty of data, then just toss that variable into the model building and charge forward. If do have plenty of data, then that variable will do no harm. If that variable is not useful, then that fact can be made clear enough in any approach to the model building (just omit that variable, construct the model again, and compare results) and in the more traditional approaches will become clear almost immediately (e.g., can do a Student’s t-test on significance of the coefficient of the variable and fail to reject the null hypothesis that the coefficient is 0).If the understanding in your slides is useful in ad writing, okay. But for ad targeting model building, don’t really have to have much understanding of the users — cats, dog, fish, birds, men, women.Of course, there are the standard men’s locker room remarks (giving away Top Secret stuff here): “Are talking about a man understanding women: But no man dumb enough to believe that he understands women could ever be smart enough to write a good ad.” “Never can tell what a woman gonna do next.” (from the movie The Big Sky. “The main unanswerable question in the universe: What does a woman want?”.
Money is indeed a quantity but VALUE IS QUALITATIVE & QUANT.And NONE of those mathematical tools (linear, nonlinear, machine learning, artificial intelligence, neural networks, probability, statistics) are properly set up to be qualifiers or evaluators.Yes, they’re great at quantifying, correlating and vector spacing discrete bits of data.Qualifying — especially the emotional reasons people engage with and buy into something — not so much.So then you might suggest doing a frequency count of the emotions, along the lines of:Q: Click here or do a thumbs up if this product makes you happy.Instruction: Now please provide your socio-demographic info —* male / female* age* geolocation* education level* household income paThat or else the system pulls it from various browser cookies and market research databases.From this, cross-tabulate in some type of matrix vector and try to find local maxima and minima with gradient descent from topography.Seems like a reasonably sound mathematical approach, hmmn?EXCEPT the frequency count of how many “happy” there are still isn’t a qualifier. Frequency count is a quantifier.So…therein is a key missing deductive logic yet lateral step which no one has spotted —Ok except for me because I’m particular about these little details, :*).
So, in common language of statistical model building, your “Click here or do a thumbs up” is your dependent variable, and your demographic data has your independent variables.Note: We just call them independent just in this narrow context; the variables are likely not independent in any usual more general sense and, indeed, if they were they would be useless in the model building.So, we collect this data for some thousands of Web site users or some such.Now we use that data to build a statistical model that uses the independent variables to predict the dependent variable.If we do a good job in the model building, we check that our work satisfies some fairly meager assumptions and our model passes our testing; then we should have something of interest, maybe valuable.What do we have?With meager assumptions, given one more person, the values for them on the independent variables, and our model, we can predict fairly accurately their response to your “Click here or do a thumbs up”.That’s what we get: A model that fairly accurately predicts clicks. The clicks can be about their deepest, most existential, convoluted, inexplicable, incomprehensible, non-cognitive, irrational, raging, passionate emotions, but, still, we can predict the clicks.Of course, if their clicks are based on coin flipping, then building an accurate model will be a severe challenge, in practical terms, too severe. Instead we will be right on average about 50% of the time. Period.And generally the more qualitative the question, the more difficult it will be to build an accurate model.But, with meager assumptions, from our testing, we will know how accurate our model is. So, our model building is not guaranteed to be successful. But the qualitative aspect is not a severe obstacle.In all of this predictive model building, we don’t claim to have obtained good understanding of the deep emotions of the people — we’re just predicting clicks.There is a now classic reason for hope: There is fairly strong empirical evidence that people are less complicated than we might guess. It’s an old story:We can make out a multiple choice test with, say, 500 questions. We can give that test to each of, say, 100,000 people. Then we can analyze the data and find, in classic linear algebra, 500 orthogonal eigenvectors and 500 corresponding eigenvalues. There’s some excellent open software for this called LINPACK.Then — roughly, I’m in a hurry to get dinner — we can get two matrices, A and B where matrix A has, say, 14 rows and 500 columns. Then for any one of the 100,000 people, we can multiply their 500 test answers by matrix A and get 14 numbers — that person’s factor scores. Turns out, these 14 numbers are from the 14 eigenvectors with the 14 largest eigenvalues.Then with matrix B we can multiply by the 14 factor scores and fairly accurately reproduce that person’s 500 answers.The one pair of matrices A, B found serve this way for each of the 100,000 people.Intuitive Conclusion: People are creatures of about 14 dimensions. For about anything want to know about a person, their 14 factor scores and matrix B will suffice.Moreover, the factor scores would not be much more accurate if the questionnaire had 2000 questions instead of 500, or much less accurate if there were 200 questions instead of 500.Moreover, ask nearly any wide variety of questions and have a decent shot at getting some fairly accurate factor scores.Roughly, each of the factors measures some fundamental aspect of people; for a given person we can estimate their factor scores from nearly any wide variety of questions about that person; and we can use the factor scores to answer nearly any questions about the person.In a sense, after learning a lot about a person, there can’t be much more to learn.Quantitative, qualitative, the situation is much the same.The subject is principle components analysis, which is just some cute linear algebra and in psychology, etc. factor analysis.The linear algebra is some rock solid mathematics and beyond any question. For the psychology, that is less solid, and some of the history is unpleasant.This stuff about the roles of eigenvalues and eigenvectors holds for time-invariant linear systems of wide variety; principle components, really, is just a special case.Linear algebra is a very important subject, and I did well in it: I’d done a lot of study and applications on my own for my career, own education, etc. But in my independent studies, I did cheat: The book I studied the hardest was Halmos, Finite Dimensional Vector Spaces, that he wrote when he was an assistant to von Neumann at the Institute for Advanced Study in Princeton. The book is linear algebra presented as a baby version of von Neumann’s Hilbert space theory. It’s one of the crown jewels of math texts — has been used as one of three texts for Harvard’s Math55. But I also studied a whole stack of related texts, made applications, did related work, etc.Then I got pushed into an actual linear algebra course, an advanced, second course, from no doubt one of the best linear algebra experts in the world. I said that I doubted I needed the course, and all I got back from the profs were patronizing smiles. Gads. I should have bet money, with long odds — never give a sucker an even break!So, the night before the first lecture I wrote out, quickly, from memory, about 80 pages of theorems and proofs that, it happened, covered about two-thirds of the course.It was a good course. I learned a few things, maybe worth a few hours of study.But there was a load of homework, graded by a grader. The work was due on Friday which meant that usually I was up until near dawn each Friday morning and short on sleep until Monday. That homework took a big bite out of my week.On one of the early homework sets, the grader made a mistake on my paper; I corrected him; and he made no more mistakes after that. Neither did I.Once my homework was late, and the prof accepted it, graded it, and remarked “I see you like coordinate free techniques.” Of course I did: I was thinking Halmos and Hilbert space, not linear algebra.About three-fourths of the way through the course, the grader came to me and said: “Do you know how you are doing in the course?”. No, I didn’t. I had been just trying to answer the questions on the homework, tests, and midterm. I didn’t think I was in trouble from low performance. Then he showed me a table, totals on homework and tests and the mid-term, and I was the class leader on all three by wide margins. Kept that up including on the final exam and the associated Ph.D. qualifying exam.Poor professor: Eventually he got to the polar decomposition, yes, related to principle components and much more, and I got so excited that finally he had gotten to it that I blurted out in class, “That’s my favorite theorem!”. That result reduces everything that any matrix can do to something highly intuitive and just dirt simple: All a square matrix can do is rotate and reflect and preserve distances and then stretch or shrink on orthogonal axes. Done. And there is a really short proof. My favorite result. The prof responded, “Thank you Mr. Halmos.” and got flustered and didn’t finish the proof. Poor other students: Who did they think they were competing with for grades! I hadn’t been trying to blow away all the other students, but I should have placed a bet at the beginning.I’ve done the derivations for principle components many times and have various notes of my own plus my class notes from the course plus stacks of well regarded relevant books. I don’t want to go into all the linear algebra details here — I need to get dinner!
Math moved away from that idea about a decade or more ago for data, which is why Ayasdi is interesting – topological structures allow for more complicated shapes.The matrix isn’t interesting if in order to produce it you forgot something important. Which is highly likely considering the amount of collinearity in marketing.
Math moved away from that idea about a decade or more ago for data, Can’t happen: That would be like saying that bookkeeping and accounting moved away from arithmetic.For some problems, people can look for some techniques that work better than principle components, but principle components will never go away — for data compression, dimensionality reduction, describing people, etc. Why? Often it works, often very well. Which is highly likely considering the amount of collinearity in marketing. For principle components analysis, collinearity should not be a consideration or should be at most only a trivial one. In the math of principle components, lack of collinearity is not one of the assumptions.For a lot in classic regression analysis, commonly people are more afraid of collinearity than they should be.In simple terms, we are projecting onto a plane. If the plane has 10 dimensions and is from all linear combinations of some 10 vectors we do have and someone gives us 25 more vectors in that plane, then the projection we want is still the same and the extra 25 vectors should be of little or no concern. Yes, from some approaches to the calculations, the extra 25 vectors can result in a matrix with no inverse. And if the original 10 vectors have collinearity, then, with some approaches, there can be some numerical issues.But there are simple ways around all of these old issues and, indeed, most of the concerns about over-fitting.Again, mostly all we want is just a projection onto a plane, and that’s not hard, not mathematically, numerically, in theory, or in practice.I’ll go ahead and outline some of this for classic regression:Suppose we have positive integers m and n and are given matrices m x 1 y and m x n X.In practice, we may have n variables and values for all n variables on each of m people, and those values are the components of X. Each row of y and X is for some one person, and each column is for some one variable. Typically we want m much greater than n, but I won’t use such an assumption in the derivations.We want n x 1 b so that Xb is is our closest approximation to y. By any of several classic separation theorems, Xb is the unique projection of y onto the vector subspace spanned by the columns of X. The Xb is unique because it is the projection, and in this situation projections are unique. But, yes, the b may not be unique.So, we want (Xb – y) to be orthogonal to each of the columns of X — that’s the necessary and sufficient condition for Xb being the projection and also for minimizing ||Xb – y||^2 — least squares.So, from this orthogonality, with prime for matrix transpose, we wantX'(Xb – y) = 0that is, the n x 1 vector of zeros.So, we have thatX’Xb = X’y.So, this is a system of n linear equations in n unknowns.From our separation theorem, we know that this system of equations has at least one solution. And we know that in case of more than one solution, all of those solutions give the same projection Xb.So, we solve for b. Maybe n x n matrix X’X has no inverse. In that case, we can’t just writeb = (X’X)^(-1)X’yNo problem. Instead, we just solve the systemX’Xb = X’y.say, just by Gauss elimination. I’ve got some rock solid C code for you if you wish.So, presto, bingo, find any b that solvesX’Xb = X’y,and the coveted projection, which is unique, is just Xb.And I said nothing about m > n, matrix rank, matrix condition number, or collinearity — didn’t need to.And, notice, I never took a partial derivative from calculus to have the necessary condition for a local minimum.More can be said, on over-fitting, etc., but I need dinner — an omelet.I dreamed up the above derivations — I’ve never found them elsewhere. So, you are one of the first to know! How ’bout that.
Ok, so I did the online Stanford Machine Learning course by Andrew Ng (now Baidu, ex-Google) a few years back.The world, especially with AI, is moving from Linear Algebra to Markov and Topography over Hilbert.Still…MACHINE LEARNING & MATHS IS MISSING A KEY.This key can’t be found in Halmos, Doob, Loeve, Breiman, Neveu, Chung, Cinlar, Gihman and Skorohod, Dynkin, Karatzas and Shreve, Blumenthal and Getoor et al.The reason is because the key exists in Art, Nature and Biochemistry — NOT IN MATHS OR QUANTUM PHYSICS (YET).I know this because I invented and crafted a key after going through Bayes, Markov, linear algebra, matrix vectors, Hilbert, Fourier, Hamiltonian, Brownian, Schrödinger, Gödel and others and determining they didn’t do what needs to be done.The psychology frameworks are also all amiss. Not because the mathematics is wrong but because the psychology parameters for the Bell curve are incomplete.
Yes, from some approaches to the calculations, the extra 25 vectors can result in a matrix with no inverse.Actually, that’s the usual situation, which is highly problematic and why Gunnar Carlsson got Darpa and IARPA as customers, and I just recently found out is very likely to have my medical records as part of the document set that one of their customers is working with on a research basis.Those extra 25 vectors do matter in a large number of fields where there is a lot of cross interaction – marketing being one of them (the other is computational biology and cancer research). We don’t want a projection into a plane – we want one that is usable and correct. hence why TDA came into being in the first place.https://en.wikipedia.org/wi…And I have no idea why this is, but understanding vectors in linear algebra in 2d (or more!) spaces is way easier to understand with properly formatted code becase of Arrays. They are awesome.
Those extra 25 vectors do matter in a large number of fields where there is a lot of cross interaction – marketing being one of them (the other is computational biology and cancer research). In my post you responded to, the extra 25 vectors were assumed to be in the plane of the other 10 vectors or nearly so. With collinearity, we have to have all the vectors nearly in the plane of the other 10.So, in simple terms, the extra 25 are just redundant and, thus, should be harmless.In particular, since the extra 25 are in the plane or nearly so of the other 10, the extra 25 are linear combinations, that is, a very simple function of, the other 10. Really, a bit tough to see how the 25 could add or detract much from the other 10, collinearity or not.I’m having a hard time understanding just where in “marketing” or anything else the extra 25 — they are essentially just redundant — could hurt very much.I do realize that for years, in a lot of applied statistics from people with meager math backgrounds, collinearity has been regarded as an evil monster. I just have to conclude that these people need to hear some good news as in the math I wrote out in my post.Don’t believe me; instead, just read the math I wrote out. It’s perfectly good math, with only slight tweaks as solid as any math can be. It’s true. Check it for yourself. That’s one of the main advantages of math — proofs we can check.The main issue of a monster is looking for accurate values of some coefficients. In classic regression, the coefficients are the usual ones, that is, from the solution of the system of linear equations called the normal equations, that is, as in my post,X’Xb = X’y.So, want accurate values for the components of b. Why? Because each such component is supposed to be used as the the measure of the size of the effect of a one unit change in the corresponding variable — for various reasons, without more assumptions, usually nearly impossible to verify in practice, this is fishy stuff anyway. People also want to do hypothesis tests of significance on the components of b and get confidence intervals on predicted values — more assumptions needed that are nearly impossible to verify in practice.Really, though, what get are just the fitted values, the Xb, which are really just the unique projection onto the plane spanned by the 10 vectors, whether have the other 25 or not and a corresponding statistical model.For applying the resulting model, there are ways that are easier, and need fewer assumptions, than a lot with multivariate Gaussian, homoscedasticity, etc.Sure, maybe don’t want just to project onto a plane. But a plane does have some advantages: E.g., commonly in practice, the function being approximated is continuous and locally differentiable and not horribly badly behaved so that basically the plane in question is a tangent plane, a local linear approximation, from differentiation.But, okay, there are some ways to get somewhat more generality still from something like classic regression.Yes, still, if have enough data, which explodes exponentially as the number of variables increases, the best approach is just old cross tabulation. That’s the best non-linear fitting (thank you Radon-Nikodym theorem).So, linear regression is how to make use of meager data; cross tabulation, for large or enormous kinds of data; and some other options between these two extremes.In all of this, basically we are trying to approximate some function f where y = f(x) for a scalar y and a vector x. Then with our approximation to f, we have some vector z and want, say, w = f(z). That’s what’s going on.For topological data analysis, that has very different objectives, techniques, and applications. And I have no idea why this is, but understanding vectors in linear algebra in 2d (or more!) spaces is way easier to understand with properly formatted code becase of Arrays. They are awesome. I do the thinking about vectors essentially only in terms of math, written on paper, typed into TeX, etc. but not computer software. The computer only does what it is told to do, and software is just how to tell the computer what to do. For knowing what to tell the computer, that’s either obvious or from math, science, engineering, bookkeeping, accounting, finance, etc.
hahahah, no one measures clicks anymore because of scale and blindness. Less than .01% of ads online of any type gets clicks.However, we can actually see brand recall. And we can tie back into purchases at some point, depending on the thingFurthermore, effectiveness of a given ad and media choice is measured against total weight of all media and marketing spend choices on a per person and per frequency of touchs model. marketing ain’t in a vacuum, and coupons cost money too. So does weird packaging. Someone has to make the packaging. And coupons!! Don’t get me started on coupons.And this is before all the pieces of the ad and brand could be weighted independently of audience choices and media choices.
Good, thanks for the larger picture.But to a guy running ads on a Web site or in a mobile app, ad targeting is still important, about all he can do is something much like what I outlined. Maybe clicks are 0.01%, but they are still important enough to fund Google, Facebook, etc. Mary Meeker at KPCB has long said ballpark $2 per 1000 ads displayed.
Buyer can cuts lots of deals, even with a 5k ad budget for 6 months. You don’t have to buy on a click or action basis even in that group. Plus even within the adwords bidder, you can force the machine engine to do some pretty odd things (which I actually have confirmed by google’s reps) So clicks are not the only optionThe biggest money making chunks of Facebook and Google are things like Atlas and DART respectively – most of which are designed to buy on a not CPC basis at all.$2/CPM over what kind of spread and segementation? Some ads just to display have a bid floor around 50/CPM (if I am not mistake) There are a whole lot of things going into that number that should not be compressed together – and how a buyer and a seller actually meet and tango is really complicated.
Buyer can cuts lots of deals, even with a 5k ad budget for 6 months. You don’t have to buy on a click or action basis even in that group. Plus even within the adwords bidder, you can force the machine engine to do some pretty odd things (which I actually have confirmed by google’s reps) So clicks are not the only option I suspected that the Web site and mobile app ad business was sometimes more complicated than just Mary Meeker’s $2 per 1000 ads displayed (revenue per thousand, RPM), charge per click, charge per sales dollars (whatever the popular phrase is for that).Thanks for the introduction to the real world of ad buying.I got my 101 level education on that ad business in part from: Ad Networks: Why it’s better than ever to be a targeted content siteJuly 24, 2007 12:50 AMJeremy Liew But there is the old report that the Canadian match making site Plenty of Fish was long just one guy, two old Dell servers, ads just from Google, and $10 million a year in revenue.And recently there washttp://www.businessinsider….One guy launched a website and made millions without hiring a single employee — now he’s sold it and could make $100 millionAlyson ShontellJul. 9, 2015, 9:00 AMViralNova, a Buzzfeed-like media startup run by Scott DeLong, has been acquired by digital-media company Zealot Networks in a cash and stock deal that could be worth as much as $100 million. Reading on, he got all his ads just via Google.Now that I have my software running, I hope that soon my site will go live (sooner if I write fewer math tutorials), and at least just at first I’ll be willing to get ads from nearly anywhere that pays.For anything like Mary Meeker’s $2 RPM, if a Web site can get enough traffic, then there’s a surprisingly large amount of revenue available per dollar of capex and dollar of opex. E.g., that’s essentially why Google and Facebook have so much cash to throw around and why people have such high hopes for Twitter, PInterest, SnapChat, InstaGram, etc.Later I’ll do some proprietary ad targeting — right, more math.If it pays for me to get into some complicated negotiations about ad campaigns, etc., then that’s what I’ll do.Thanks for the tutorial.
urm, you do know I can write my own scraper in python?And I really don’t look like that. I have fuzzy hair.
I’ve heard that Python has some good packages for Web crawling, etc. Microsoft’s Iron Python is compiled and also gives access to the .NET Framework I’ve been using for the code of my startup.Maybe eventually I’ll use some Python, but for now I’ve gotten good results with just the open source cURL and some simple macros for my favorite editor and my favorite scripting language.I found the picture of the girl from a Google image search “Disney princess” — there were a lot of results, and I picked one with a relatively good expression.
The lady isn’t going to talk yet about how to build that stuff.
I would love to see the same data on followers that engage with tweets you post.. Engagement by audience(s) metrics seem more meaningful?
What’s the technology Twitter uses to get these stats? How would they know anyone’s income, preferences, etc? (DMP? Retargeting???)
“If I had a wish, it would be for a … a more female audience, and a broader demographic in terms of wealth (or lack thereof).”Glad to know I am helping 😉 On the other hand, I’m sure you’re outpacing other vc’s in that department.
Female, from London 🙂
hello london!
I am a big fan of your blog and was so excited to read your comments about want to have a larger female following. I just sent your great blog to my followers, most of which are women, and people of color.
hi
Ha, at first I thought you meant men who are “overwhelmingly wealthy” and then read the numbers.Well, if it makes you feel any better, I am proof that there are a few exceptions to some of these stats. Won’t say which ones. 😉
Not wealthy yet. Still a lady. 🙂
“global audience, a more female audience, and a broader demographic in terms of wealth”Find blogs with demographics skewed towards that audience (not sure how) to help select/influence your post topicsRandom idea: diverse guest posts and topics- Specific international startup guest posts (Zemanta is still active right?)- strong female leadership in your community, investors / entrepreneurs / devs- not sure how to attract a less affluent readership though. focus on college age topics (job search challenges, living in great locations, life changing experiences). Specific examples of general investment philosophies for retail investors who don’t general invest in startups.- education posts are a great topic for a more diverse audience