What's Next In Computing
Chris Dixon posted an excellent roadmap for thinking about what is next in computing.
I particularly like this visual from Chris’ post:
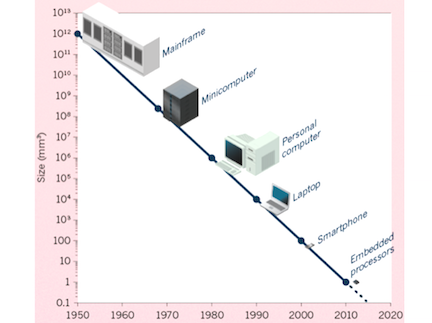
My big takeaway from Chris’ post is that these cheap embedded processors are going to be built into everything in the coming years (cars, watches, earpieces, thermostats, etc) and advances in AI will make all the data they produce increasingly useful and disruptive. Chris goes on to tie this megatrend to things like self driving cars, drones, wearables, and VR.
While I think all of those things are coming and investable, I wonder if there is something more fundamental in the combination of ubiquitous computing and artificial intelligence that would be the next big computing platform. We are due for one soon. This visual is also from Chris’ post.
What is the dos/windows, netscape, and iOS of this coming era? If we can figure that out, then we are onto something.
Comments (Archived):
I think it’s a commons-like cloud full of shared big data derived from sensors and apps that is the platform for building analytics derived apps.
I hope all this data doesn’t end up being owned by few companies, which seems inevitable the way things are shaping. Having it accessible to all would create a level playing field.
Agreed, it’s a very mainframe centric architecture right now, meaning one firm owns the clients, servers, apps and data for a given IOT application, which makes it hard to really unlock data and potential of IOT for things like Smart Cities when the water department has their data locked up in vendor A while the traffic department has their data locked up with vendor B, and so on. We need an OpenData platform to act as the commons for data like the internet did for networking.
Unfortunately, the “network effects” economy tends to favor those who get big fast. So it will definitely end up controlled unless there is some legislation that makes all personal data portable.
I hope that someone is figuring out how to make everything connected secure.
Nope. I can assure you they are not. I’m in the field of “information security” and this is one of the biggest threats being identified by the community. The level of security operations now is not up to the scale of this future. The only solution is to design it right, which it isn’t.
Scary.
The [unfortunate] law of greed. Make money first and deal with the [inevitable] calamities later [never]. Build the nuke plants on fault lines near the ocean. Who cares about the grandkids? Launch those drones and autopiloted cars. Keep the spaghetti code flowing; the economy growing.
Or law of incompetence. Or both.
Unfortunately, this is exactly why we are in the state we are in. I don’t think there’s an easy solution, either. The big companies will certainly hire all of the computer science and security graduate students, but they don’t fund the next level of security research. I saw a great talk about this at the 2014 FIRST Conference by Eugene Spafford. His predictions were sort of dire, but true:1. The very concept of fixing security later is flawed. It has to be designed to be secure in the first place, otherwise you are just patching it. And eventually, like we see now, we can’t keep up with the patches and patching everything because more of a job than making cool new stuff.2. The fact that incident response teams come in and clean everything up and make the problems go away for a minute just “enables bad habits and bad attitudes” (Spaf).
SSL should still do the job, any reason why it shouldn’t?
My contention is that it’s not doing the job now. How is it going to hold up with exponentially more nodes on the network? Also, “security” means a lot of different things. Transport Layer Security (TLS) is good for some things, but it doesn’t present, say, some hackers from penetrating an organization and dumping all of your personal data on the internet. Nor does it in any way ensure that your decade worth of health data from all of your sensors doesn’t disappear or get tampered with somehow.
if you want to connect it to your body, definitely
I wonder if dynamic location or proximity doesn’t play into this.With all these micro devices connected, the relationship between them and people moving around maps the world in a completely different and dynamic way.Beyond a physical web to a broader view of how the world is moving and changing.
that could be the big opportunity for a company like Foursquare
Yup but honestly i don’t really understand FourSquare any longer.Used to but can’t wrap my head around where they are going. My shortcoming.
it’s evolution
This is definitely one of the next big areas. The sheer volume of sensors with computers will be able to deliver data on a scale we are just now beginning to comprehend. Imagine when the highway is bumper-to-bumper with self-driving cars all communicating with each other and with the passengers and their devices. There will be a time when they will outlaw “real” drives as too inefficient and dangerous. All of that data and meta data paint a totally different future reality for us.Within a few years, we will be walking around with something in our pockets that has the ability to store everything that’s on the internet right.And we are thinking internet security is hard now. Nobody is designing that security future. Nobody is investing in the research to make that level of data and personal information secure.It’s a huge opportunity and a huge risk. Very exciting stuff.
Agree.Free location data will be ubiquitous.So what to do with it is truly exciting.
It’s a whole new frontier, IMO. The network effect is really staggering on this front and potentially out-scales other networks exponentially.
“What is the dos/windows, netscape, and iOS of this coming era? If we can figure that out, then we are onto something.”Ubiquitous surveillance…..uh, I mean the Internet of Things. All the things.
I’m sure Google and others are working on it, but for some startup mudging around in the weeds there is probably a massive opportunity for (IoT) search there.
I thought I read about an IoT search engine. Can’t remember name tho.
saw tweetstorm yesterday along the lines of Google created the best business model of all time and used crazy employee perks as a way of diluting profits. thus reducing investor expectations (him) and throwing competitors/regulators off the scent (me).it seems to me the industry as a whole is doing the same when we use terms like ‘ubiquitious computing’ and ‘AI’. Normals just hear techspeak and switch off. They don’t grok the gargantum world changing power of these things or the ramifcations they will have on all our futures. Thus they don’t engage. Less people fighting for the spoils.Hiding in plain sight. Awesome.
I think spending an hour or so with the US Tax Code and maybe reading some motions and court orders from In Re: High-Tech Employee Antitrust Litigation would quickly disabuse him of that notion.
Normals 🙂
I hear the techspeak and plunk my head in the sand, worried about kids doped up on VR even though I grok the world-changing power of ubiquitous computing.
Something you worry about? Kids getting doped up on it?
Doped up in the sense of tuning way out, yes, and at the expense of other things, in real life, of course. I’m thinking of Sherry Turkle’s research on conversation for example. Or Fred’s recent post about seeing young people sit down for dinner and engage with their own phones for long stretches instead of being fully present. All of us with our phones at times …
Interestingly, my 78 year old mother in law visited recently and reported to me, wide eyed, how AI was going to bring about the end of the world. Because Bill Gates said so on “Frontline.”
What’s interesting is that your mother in law was raised in an era when people who were famous (in a science sense) were more good than lucky. As such she probably puts a bit to much credence on what she hears someone say on Frontline or 60 Minutes (of a tech nature).
Yep – and also age seems to have had a multiplier effect on her potential for nihilism.
They don’t grok the gargantum world changing power of these things or the ramifcations they will have on all our futures. Thus they don’t engage. Less people fighting for the spoils.Well it’s not like normals would be competition for any idea a tech person was doing anyway (if I read your comment correctly).Also normals don’t really care that much about all of the embedded things which are actually solutions in search of a market. They want an ice maker on the front of the fridge and they want automatic defrosting they don’t really need (at least not the majority of them) to have the fridge tell them what they are running low on.
Interesting read. Notably absent from Chris’s post is 3D Printing, which I think has all sorts of potential as it improves.
so ‘cloud’ means a centralised server architecture?that would be a ‘great’ point of attack for hackers and nation state cyber armies.the blockchain has to be deployed, and the more devices there are connected the more secure the block architecture becomes. it’s another network effect.Ethereum positions itself as ‘the world computer’.
The article was heavy covering the hardware side (hence the title Computing), as a lever for software evolutions.Although we are making leaps and bounds progress in hardware and devices, I don’t believe that software has caught up yet. There is no Moore’s Law equivalent for software. A hardware device that’s not perfect doesn’t see the light of day, whereas we keep working on software that doesn’t do a good job and we accept that.In my opinion, there are high expectations for AI, AR and VR. If they deliver, will they be affordable to, and understandable by the masses, or just the techno elites?
NIcely put.Isn’t availability of data always behind our ability to use it smartly?
Maybe…but as you well know, pushing a button is a lot easier than interacting with data or pretending to “talk” to your computer.I remember futuristic depictions about us talking to our computers as assistants, and that was supposed to arrive in 1997. Yet, 20 years later, we’re still trying to talk to our computers, but they don’t want to talk to us. They are happy talking to each other, instead 🙂
Of course.There are just beacons everywhere and more coming all the time pushing out data that is honestly not being used in interesting ways.Someone is going to harness it.
I remember futuristic depictionsEntirely self driving cars are an example of futuristic thinking that won’t happen in our lifetimes. People seem to think that just because progress is made in one area it means that we will make progress on some wish list item. Meanwhile I am thinking that back in 1996 nobody would have thought we’d still have a big spam problem 20 years later. Ditto for everyone owning an airplane back in the 30’s or 40’s.
Do we really have a big spam problem? I certainly don’t – do you provide your email yourself?
It depends on what you consider “problem”. If you are willing to accept that any particular email isn’t that critical and can be ignored then you don’t have a problem. Most people I think probably (even if they use gmail) don’t have spam automatically delete, they still review the spam folder just to make sure they didn’t miss something. Not only that but it is a problem. Because legitimate businesses can send out legitimate business communications to their customers and it ends up in a spam folder. And I have sent emails to my wife and others that I know (that I communicate on a regular basis with) and they end up in the spam folder. So yes it’s a problem and it hasn’t been solved. And no I don’t want to have to pay some organization to certify that my mail is legit either.
It is a very small problem these days, relative to say, phishing or hacking. The occasional mis-classification perhaps, but only an issue for those few people that expect to receive emails from strangers on a daily basis. Most businesses now have online portals where users can access their data.
Don’t agree. (And I’ve been doing this for 20 years and run a few email servers by the way…)
Gmail’s spam rate is now less than 0.1 percent with under 0.05% false positive rate (took numbers from Wired). You really mean to say that you’d have considered those numbers as bad 20 years ago? I agree with you that spam can be an issue if you run your own email services, but as far as technologies go in general, it is not a problem that the majority of web users have to battle with.
The entire world is not on gmail. Plus gmail has many ephemeral, new or rarely used accounts. I have a few gmail accounts and they don’t get spam because they are not used that much and haven’t been around that long.
My point is that spam was a problem universally, 15-20 years ago. Almost everyone that had a public email address received spam in their primary inbox on a daily basis. As you said, it is now an edge case problem, and not a ‘big’ problem like it was two decades ago. It took a lot of work, by a lot of people to make those improvements.
Sure but making people pay money to have their email end up in the right place is not a technical solution to a problem (which was part of my point). It’s a business solution to a problem. The fact is this. They have not been able to program computers to recognize what is spam and what is not yet all of us in our brains are very accurate on that subject or at least the majority of us are when we see a pattern. Hence my point about computers and totally self driving cars and this idea of technology advances because of Moore’s law (which to me was also a business model so as not to kill the golden goose and unroll to fast of a pace in hardware advances.)
I am not saying that spam does not exist. It does. Just like measles still exists. And kills a more than 100k people a year. Which may seem like a ‘big’ problem until you consider the fact that nations providing basis infant healthcare means that the US went more than a decade without a single measles fatality. Is spam a ‘big’ problem today? For 99% of people, no. If you are an email marketer, and your emails are being discarded as spam (which they technically are), then maybe it is a problem for you, but it is not the same problem as the daily spam deluge of the late 90s and early 00s.
I get my e-mail service from my ISP, and AFAIK they send me everything. The spam I get is less than 1% of the total.Apparently various other efforts shut down the spam at the source points.
By the way if this still wasn’t a problem (email deliverability) then some of Fred’s investments (such as returnpath.com) wouldn’t have a business model.
I think that email deliverability and spam are different things. If returnpath grows to having 900M active users then maybe my perspective on this will change.
By the way part of my point was that they haven’t fixed the edge cases in spam which is why self driving cars (totally self driving I mean) are a non starter. The stakes are to high if the AI is wrong not the same as spam.
I sometimes think that hipnotized by the allure of the cool and the hip, we systematically leave a lot of undone or poorly done work behind that nobody really notices. Progress is coming so fast that we trip over it.
Solution: Each user tracks their important senders, and each of those gives an importance value. Then the receiver scales the importance value per important sender.
Alternative solution: Let Google handle it. Google’s AI filters are light years better than any other email service in identifying spam. And continue to get better each year. It’s good enough that I use gmail’s servers for all my email accounts, even the non-gmail accounts.Someday soon, gmail users will collectively just stop checking their spam folders.
Solve spam problem: Global black list of senders.
Does built in obsolescence count as spam 🙂
won’t there be new senders, as long as spam is profitable?
Somehow, some efforts seem to be keeping down the spam: AFAIK, my e-mail has no spam filtering at all, and my spam problem is just too small to worry about.
This comment has stuck with me.Cause while for certain lots didn’t happen. But so so much that none of us did, most certainly did.
William Mougayar:Yours thoughts on the subject is like when a thousand pound gorilla sits on something. The words are powerful. But also is the funding behind a product or space. The masses have no idea that it is coming until it is here. Then it will either be adopted or fail.Software appeared to always be a complement to hardware.
…complement…
Pete Griffiths:Predictive text sometimes requires a chaperone.
🙂
Pete Griffiths:http://youtu.be/20elMaVZ9lgPredictive text requires a chaperone.
whereas we keep working on software that doesn’t do a good job and we accept thatExactly not to mention that some or all of this is as a result of the software and/or services being free or low cost. And even with paid items there is really no comparison to how people are willing to pay and get a sub par product (software or hardware) computing wise vs. other items they buy which will be promptly fixed or returned to the merchant. People have just simply learned to accept faults in software and/or blame it on themselves vs. the supplier.
Well put.If you pay peanuts, you get monkeys.
Lots of times you get monkeys anyways 🙂
Well, pay is only a part of the equation. Other parts include caveat emptor, look before you leap, etc.If you neglect those you get monkeys too, or sometimes baboons, chimps or 800-pound gorillas – which are all apes too 🙂
It is worse than that for me !I’ve learned to accept faults in hardware as well.Your luck may vary ?
Starting in the late’90’s, Bill Gates talked up Voice Recognition as the next big mainstream trend. Its has so not happened that the VR acronym now stands for something else.Almost no major tech trend has been identified by someone in side of tech: PC started in clubs populated by dorkball electronics enthusiasts, Web started by DARPA, search by a startup no one wanted to buy and social started @ Harvard…..Harvard!If you use history as a guide, any idea that is promoted by big tech is not the answer, which would X-out of all Fred’s suggestions.
The new tech will be experimented with primarily outside Silicon Valley. There are already IOT groups in Michigan of hobbyists, I am attending one of those meetings tonight.People will building stuff with those $5 wi-fi equipped boards Chris speaks about. They will be wholly uneconomic, not practical and maybe even laughed at by others.But then the size of those boards and the cost will shrink by 90%, these little projects will become practical and it will lead to a revolution in embedded artificial intelligence.
AI maybe, IoT seems more probably……economics, integration into existing HW platforms, insertion (pets, people, food) etc.
To be sure, none of the big techco’s in SV have solved Voice Recognition. It’s not just about the noise issues wrt background sounds and accent recognition.MS has demoed neat narrow examples of Voice Recognition:* https://m.youtube.com/watch…* https://m.youtube.com/watch…Quite apart from accent and pronunciation variations in noisy environments, the challenge for all the major techco’s is the same: how to deal with word ambiguity, context and the subjunctive tenses in our communications (whether spoken or written).Not even Stanford and W3C have workable models for these.It literally involves us re-engineering … ALL DATA since we humans started documenting our experiences.Yes, some lightbulbs went off in my head a few years’ ago and there are systematic steps forward to solve these hardest of hard problems.Hence why I’m in SV as I type.
Yes, you have to compare voice to where we were in ’10, ’13 and current. A lot of progress. A lot of hard work forward is going to pay off big time.
You don’t think Google are making progress then? I can only speak from personal experience but I find Google Now incredibly accurate even in a noisy environment.
Everything is relative. To ordinary users, Google Now works.To AI people, there are still tons of limitations and areas for improvement. Google itself knows this:* http://time.com/google-now/
might explain why I have trouble with these sorts of speech recognition technologies. Between Adhd and the fact that I code switch between english dialects that are already localized, I must be an edge case. (https://en.wikipedia.org/wi… ). and this is with the loss of most of my new york accent, which used to be very very heavy. (cawfee anywon? kind of heavy)
Isn’t speech recognition a problem closely associated with nlp, not because of sound per say, but because accent recognition is going to also include language shifts?
There were and are some fundamentals that did or should have been sufficient for some good predictions:(1) For the first microprocessors:Use a microprocessor and some software to get rid of a huge board full of custom designed, discrete digital electronics. One example: The control and logic for the Diablo and then Xerox daisy wheel printers. The electronics industry saw that coming. More generally, the US DoD and NASA pushed really HARD with super big bucks for everything that could be done with transistors, integrated circuits, and digital signal processing — Silicon Valley was one result. The DoD and NASA knew in very clear terms what the heck they desperately needed: Much, much more in signal processing and without vacuum tubes.Indeed, the key was the transistor, and it was pushed by Bell Labs as Bell clearly saw that they needed an amplifier much better than vacuum tubes. No accident. Instead, careful planning. And Bell saw the value for the world and, thus, as a gift to the world, gave away all patent rights. And the Nobel committee also saw the value.(2) PCs:One of the biggest labor wastes and productivity bottlenecks in the country was using the old typewriters, that is, word processing. Then a PC with a printer and some simple software, even with diskettes and without a hard disk, totally blew away the typewriters. Big. Huge. That bottleneck was easy to see, and so was the opportunity.(3) Digital Communications Networks:That digital communications networks could be powerful had been known way back to, say, the USAF getting data from far north, early warning radar stations. Later IBM did Systems Network Architecture (SNA) for, say, the reservation terminals for American Airlines. What IBM did was severely constrained by (i) the high cost of digital electronics and (ii) the very low communications data rates available at anything like reasonable costs. There was Ethernet and Token Ring and much more.Finally computer hardware and digital data rates got cheap enough for TCP/IP, and it took off. The three main issues were (i) digital instead of analog, (ii) end to end reliability instead of link by link reliability, and (iii) the routing. For the growth, the main issue was data rate, and there Bell Labs had seen the problem and worked out the solution long before — GaAlAs heterojunction solid state lasers down optical fibers. And IBM had worked out an astounding amplifier — just wrap it around the fiber and amplify the signal without detecting or regenerating it. The initial design of TCP/IP was not nearly what we have today. That high communications data rate would be a biggie was clearly seen by Bell and their predictions of video phones, which we now have.(4) Google:A computer version of an old library card catalog subject index with results sorted by a gross measure of popularity, e.g., page rank. For the value early on, few people saw the potential of the Internet. E.g., dial up connections from home or small office was a heck of a bottleneck. But with cable TV and, then, digital modems over the cables and faster PCs, Windows XP, etc., now the crucial pieces were in place.Surprise: Clearly quite early on, Bezos saw that soon enough there would be plenty of Internet data rate to homes to permit sending lots of complicated Web pages with lots of high quality images, sound, video, etc. Nice guess! I thought that Amazon would hit a ceiling of selling just books and records because much of the rest required too much additional information, e.g., all those pictures. I was thinking, say, 300 bits per second or 9600 bits per second instead of 20 million bits per second. I just didn’t guess about the factor of 2,000 or 60,000! Big mistake!I’ll.never.do.that.again!This stuff is not wildly unpredictable.
“any idea that is promoted by big tech is not the answer, which would X-out of all Fred’s suggestions.”Maybe because new APIs are not consumer facing tools?Network-effect power-tools that provide consumers with collectively transparent “jobs to be done” social-assemblers for-the-rest-of-us may indeed need to sit atop such complex APIs but it is this consumer-control-layer that will define all of the next truly big things. Big things are things accessible to massive public reuse/participation/ingenuity.Tame those APIs to be more generic, reusable, open and able to talk to standardized public data warehouses and then wrapping them in an enduser social-construction toolkit interface, oh but wait. . . that’s right there is no winner take all in that !The emerging atomic-table of generically functioning network-effect narratives/metaphors now being osmotically surfaced/distilled into our collective consciousness as a distinct set of namable social building blocks via the present crop of mobile Apps will at some point coalesce into its own high-level enduser platform-enabling mass-culture network-effect toolset/language/imagery .That evolutionary process seems doomed to suffer the time dilation slings and arrows of bottom-up-only experimentation as little-to-no top-down cross disciplinary analogue/metaphoric framing has yet arrived at the silicon valley social reorg-party ?Just maybe the hull-speed of corporate culture as presently formulated, that is to say capitalism that has not quite evolved up to its advertised organic competition potential, now imposes itself as an overarching hull-speed limit to the every fabric/potential of a network-effect culture.
IMHO they will be affordable and understandable and ubiquitous. (see my post)
My specific criticism in the comments under the article were the lack of discussion of impact on the compute cycles coming from developments in the infrastructure layers (network and service provider). These developments are not mutually exclusive.So they will have an important impact on the next compute cycle. Watch what the FCC did last week to LinearTV model. A 1-2 punch if ever there was one. And video is dominating this compute cycle. As are massively distributed sensors. They all require connectivity with much better performance and lower cost than exist today. And a payment model is necessary that’s not based on ads, as I point out above.
Steve Jurvetson & Rose Law (not Moore’s).The future is a triangulation between Jurvetson and Dixon’s views plus AI at data structure level.I agree with the whole embedded systems thing and UX via voice+gestures rather than what we currently have.Sure, expectations are high…Yet progress is made not by linear increments but by leaps of imagination, execution and brave hearts.The tech components are emerging. It’s a matter of integrating them coherently.
Twain, what is your estimate on the date we will have quantum coprocessors generally available and on similar prices as the most advanced GPUs we have today?
So the thing is … We don’t need quantum co-processors when we recognize and accept that language and general data is NOT a Bayesian phenomena (probabilistic correlation).I was showing and discussing my system with a Chief Scientist I know (PhD AI, Oxford University) and the penny dropped in him. He said, “So, with your approach, we’d need fewer data points over time and it wouldn’t be as processing intensive!”Indeedy.And then … by serendipity (because ‘Twilight Zone’ coincidences happen in Twain’s world)…… This research was published last week:* http://phys.org/news/2016-0…Well, guess what? I made a bet years ago that measuring words as correlations within Newtonian vector spaces and as Brownian motion in a box wasn’t the right approach.I had already decided to go straight to the sphere model and Einstein’s gravitational waves for language and meaning in data+AI — EVEN BEFORE PEOPLE CLEVERER THAN ME DISCOVERED EINSTEIN’S GRAVITATIONAL WAVES EXIST.Because I’m “mad artist-scientist” in that way! After all, even as a teenager, I was obsessed with spheres that could be in constant suspended state as well as free-flowing and shape-changing in aqueous liquids (like Lava lamp) when I worked in product labs of major chemco.A bit like Magritte’s piece on spheres.Now I simply re-apply that knowhow to code data+AI.LOL. It’s not anything Stanford, Google, Facebook et al could imagine because their PhDs didn’t have those hands-on teenage experiences!
I am asking for a toy to tinker with and you are selling me tickets for the great launch :-)Rephrasing, when the great launch would be, or.. can I see part of your work somewhere?I will add the Magritte spheres to the inspirational material stuck on the brick and mortar wall behind me.I have on display this, to remind me about cultural diversity and the breadth of the effort. https://uploads.disquscdn.c…
The founder of Lastminute.com retweeted this link the other day about why bilingual kids are better at “thinking outside the rules”:* http://www.fastcoexist.com/…So I replied with these quotes from Picasso and Steve Jobs …I’ve been multi-lingual since I was 1 because of my parents. Being multi-lingual is why I know methods like “bag of words”, Word2Vec and similarities over vector spaces still can’t deal with:(1.) Subjunctive tenses in Latin languages; and(2.) Perceptual emotions baked within symbolic structures of Oriental languages which provides context that don’t exist in English.So … when I take apart Chomsky & Minsky’s roots for symbolic systems and Large Hadron Collider it with my knowhow from art, maths, chemistry, finance, Quantum Relativity, data+AI …It’s natural I’d solve the data meaning & understanding problems for AI differently.
Da Vinci’s a genius, of course.@fredwilson:disqus — Yes, next big computing platform could be incumbents building bigger boxes within which they correlate existing data sets by using existing legacy tools.OR it could be new entrants building whole new spheres of data and new tools ….Particularly since Nat Lang doesn’t fitted neatly into boxes and Amit Singhal of Google said, “Meaning is something that has eluded computer science. Natural language processing—or understanding what was said—is one of the key nuts we will have to crack.”No techco will crack the nut with their legacy in-the-box models any time soon :*). No matter how big their box gets.Language has curves. It’s a round peg that doesn’t fit the square.Noam Chomsky, the father of Linguistics, has long had philosophical fights with Peter Norvig of Google about whether language is probabilistic and fits into boxes:* http://www.theatlantic.com/…* http://norvig.com/chomsky.htmlChomsky makes a keen observation about cells which applies to how data transmits in our brains — as atoms not as bits nor as boxes.Meanwhile, at Deep Learning Summit 2016, Professor Chris Manning of Stanford said: “Higher level language is of a DIFFERENT NATURE to lower level pattern recognition.”Well … it’s the difference between squares and spheres and between correlation and causation. They need different tools of measurement and modeling.The next computing platform can carry on building box matrixes.Or we crack Da Vinci’s code, see sense and make systems more intelligent like us.
Based on the above we should probably talk.my handle at my handle dot com.
Lawrence, your question – “the date we will have quantum coprocessors generally available and on similar prices as GPUs…?”My answer: not soon. I love quantum computing – it has enormous promise, but so far it’s only that. It will be many years (I’d guess many decades) before these things become commonplace and inexpensive.15 years ago (when I was a physics student) quantum computing was at the analogous point for traditional computers as when Alan Turing was pursuing his idea for a general purpose computing machine.We’ve passed that point, and are now in the analogous phase where universities and research labs were building expensive computing prototypes / proof of concept machinery. (like the cool artifact on display at MIT).For the past decades it’s been funded not so much because of the promise of near-term return on investment, but mostly for defensive reasons. i.e. they have the potential to be devastating to our current security measures, so the u.s. government will continue to invest in them because we don’t want to be sitting on the sidelines while someone else builds them first.However, one day we’ll wake up and they’ll have not only caught up to transistor computing, but have far surpassed it. For a few narrowly-defined computing exercises, that day will come fairly soon, but for general purpose computing, that day is still far away.(there are some parallels to general AI development there, now that I think of it…)
I thought the d-wave chips were at best partial quantum according to the best available tests
What do you mean by doesn’t do a good job? Poor design/UX/UI? Inability to scale? Too many bugs? Software today, at least the stuff I use, works way better than anything I used in the past.
I mean there is a wide variation between good and bad software and we seem to put up with it more than we put up with bad hardware.
That is completely wrong, sir. Software still runs and makes the world go around. Yes u are telling it only to make yourself look smart, but please remember sir you only look smart not think smart
There is a wide variation in software. Of course, there is great software, but there is bad software too, typically reflected by bad UI, or less value from that software.Software that runs on machines & between machines is typically better than software that humans interact with.
Here’s the answer to the software+hardware problem.
VR will eat the world. Because for all the addictive, and lonely, and rich and poor, VR is the supply for most of their demands.
Next computing platform: DApps technology stack based on blockchains e.g. Ether rum, IPFS, BigChainDB https://mobile.twitter.com/…
The next MS/DOS will be distributed and have some scarce shared resource such as address space. It may look a lot like Urbit, though may not actually be Urbit. The consequence of pervasive cheap computing, SOCs, sensors, etc., is to push computing back to the user side, the opposite of promoting further centralization in the cloud. No doubt AI and quantum services will still be very useful and relevant, particularly for specific applications they are suited to, but I do not think they represent a new potential for software lock-in.
Is the IP (internet) stack distributed or centralized?
If I’m free to imagine the future, I would prefer to think address assignment would be distributed, sort of in the way that the mining of bitcoins is distributed. In my chosen example of Urbit, however, they assign network address space centrally based on a limited pool of pre-defined domains. I think this is one of the assumptions of Urbit that will cause it to fail, although the idea of a distributed computer is awesome.
You are addressing only one layer of the stack. I believe all layers will look very organic and be in a state of chaos. At times exploding out to the edge and at times collapsing back to the core. And this will happen not only from changes in the specific layer (technology, use, competitors, scale, etc…) but all the supply/demand forces in layers above and below. Settlements will serve as the price signals providing the incentives and disincentives in the process. I like to call it centralized hierarchical networking (CHN). Hopefully it sticks. Ericsson recently coined a term for 4.5G and 5G radio access networks based on “hierarchical cores”.
Interesting! This sounds like a more sophisticated view of networking, will have to read up…
The routing is distributed. But IP is not reliable — it is free to drop packets for any reason or no reason and tell no one. Sounds like a dumb idea but actually is quite bright. To make IP reliable use TCP, and it is just at the origin/destination end points. The assignment of the IP addresses, of course, is centralized as is the assignment of domain names. Then for translation of domain names, that is the domain name system, DNS, and is distributed. For authentication, that is added on and is from selected certificate authorities. Sure, heavily the technical details are in the requests for comments (RFCs) and are in effect centralized but with copies on many servers around the world.
Scary that so much of world runs on 30 year old tech protocol.
Embedded inside the human body too. Sensors that monitor glucose levels, drug levels, heartbeats, O2 levels….
Nice but whoa wait till that gets hacked too, the mind boggles. Krebs found one item already – http://krebsonsecurity.com/…
And then we will have health diversity problems…
All of this will lead to higher healthcare costs. Just like advances in medicine have led to higher healthcare costs. First people live longer and second people can more easily abuse their bodies as an unintended consequence.You know what I love the most now? Narcan! Almost in every police department and now maybe they will have them in malls and public places. So we can quickly save all of the heroin addicts and they can continue to be a drain on the rest of us.http://www.nbcnews.com/stor…https://www.themarshallproj…
I don’t think technology leads to higher costs. I think regulation and one size fits all health programs lead to higher costs. Fix that, use tech, and healthcare can get really cheap
embedded in the human body has huge huge huge issues
The real disruption will come not from the data these sensors provide, but in incentizing the owners of that data to make it accessible. Micropayments with bitcoin have not had much success, but paying for an NYT article with 4 hours of refrigerator sensor data may.
A consumer data union can provide a basis for basic income and solve some social problems in the process
Creative idea 🙂
I like the idea too, sounds like an evolution from the ad blockers, don’t block ads, unionize!
Yep, data isn’t enough when the effects of the data are long term or are of low probability (though relative risk is higher).SmokingDrinkingSpeedingSavingDietingExercisingInvestingDrugs
I agree
Data bartering.Cool idea.
These guys are starting to build towards that http://data.world/ (based out of Austin, TX)
Interesting thought.There’s a mobile ad-tech startup called Unlockd (http://www.unlockd.com/) which is (kind of) trying this out via owning the content a user sees each time they unlock a phone. They just launched with Sprint, jury is out to see whether consumes will actually go for this, but the data behind it may very well wind up being more valuable than whatever CPM ad rate they can negotiate.Anyway, as James says, data bartering. Cool idea.
Agree with your overall premise, but think it will happen differently than most expect. We’re running into privacy headwinds already. It won’t be about reducing the guesswork that goes into monetizing privacy through ads as it will be where the cost of access (communications) is subsumed into the vertically complete solution one is a part of. I call the latter the socio-economic transaction/session. See my comment above.
The computing platform of the future I’m most exited about is the human genome. I think the economic and social disruptive potential of genome editing technologies is going to be at least an order of magnitude bigger than anything we’ve seen.
ethics questions, so many of them. would you edit your genome
The next platform will be voice-controlled virtual assistant and the next computing paradigm will be deep learning NNs
Of all the comments here today, you may be the one who’s closest to having nailed it.
Go, Siri, go? Learn, machine, learn!
I think the next evolution will be an OS for AI. Sort of like iOS or Android, but where apps can be built specifically for AI, and where developers can iterate on previous versions. This OS AI would naturally be integrated into things such as cars, shipping containers, wearables, etc…
Walt Disney built an empire around knowing how important photographs are to families, that’s why Kodak was one of the first stores on Main Street. The real estate known as the personal screen will continue to be as valuable as any throughout the worldEven Steve Jobs missed this in the first iPhone.
Nice reminds me of the carousel scene in Mad Men. Also I think they are onto something re: Magicband. http://www.fastcompany.com/…I think the magicband approach could be interesting for tourism
This is my favorite comment of yours and a core behavioral truth.On the consumer side, personalizing everything is key.On the enterprise, controlling everything is its core.Will either change?
Yes. Digital economics dictate it must. Supply obsoletes in minutes/days/weeks, while there is no stopping demand or its divergence. Vertically integrated stacks will give way to horizontally scaled ecosystems that support infinite range of vertically complete solutions. No 2 demand curves are alike. Ask yourself: “do you think any two smartphone screens are exactly identical?” See my comment above.
of courseon the enterprise side this is more complex actually as consumer behaviors are much more malleable than core dynamics of the enterprise.
agreed. that’s why any discussion of a knowledge management/sharing system needs to include external interfaces & i/o empowerment for individuals in all areas of the organization. codified to assure protection of IP, secrets and future projects. i always try to look for evidence of this in KM discussions/articles and find very few out there.i started work on this concept back at Multex in 2002, but i tend to be more involved in infrastructure and service provider projects and deals; only occasionally moving up to the rarefied air of the application layer.btw, twitter’s crm announcement is interesting. i haven’t looked closely, but this needs to scale out of the twitter platform to ultimately be successful and drive users and usage back to the twitter platform. hopefully that’s what they have planned.
Disney practically invented the selfie.
Are those two goals truly compatible in the long run ?
When you are selling to the enterprise you need to understand both sides of this. So yes in a way.
Even Steve Jobs missed this in the first iPhone.How so?
No camera
It had a camera in 2007 the first iphone.
https://uploads.disquscdn.c… https://uploads.disquscdn.c…Referring to the 2007 presentation. A music device, a phone, and a Internet browsing device. Was it even mentioned in the 2007 presentation? It was an afterthought at best.Imagine if the preentation were an video camera, a music device, a phone and a Internet browsing device. It’s one device folks.
An iPod, a phone, an internet communicator… an iPod, a phone, an internet communicator… are you getting it?..(Steve Jobs at the iPhone 2007 presentation)and the world changed.We are trying to find the next shifts in complexity, I think we should be looking for it in simplicity.
Attached. Picture I took of two strangers on a cruise ship with the first iphone a few days after it was released (d. July 2, 2007). I was probably close to the only person on the cruise with an iphone judging by the reaction of everyone who saw it and especially all of the immigrant help that worked on the ship. [1] Every single waiter made a comment and wanted to hold it. People’s reactions were all like the folks in the picture….[1] Because I left the day after the iphone was released in the stores….
Cool. Did you bring a camera as well? Did you get how important this feature would be?
Sure I brought a camera as well. And yes I knew how important the feature would be. Also I was taking selfies long before you could do it with smartphones as well (so I saw the potential of a front camera).So many of the things I did before they were mainstream turned out to be more popular now then when I did them. Photography (had darkroom), rc helicopters (gas powered and expensive no drones obviously), entrepreneurship (not anywhere near what it is today with college grads), computers.
Yep, I sold chopped liver and chocolate chip cookies and was part of computer wafer manufacturing startup in college.
Correct.Photos are a distinctively important artifact because they are emotionally rich.
I agree that the problem is software. There has not been enough advances in programming to properly leverage the platforms (especially regarding security).What is extremely impressive about IBM/Watson is how they have abstracted various “subroutines” into meaningful real-world solutions. Personality profiles, matching, visualization, etc. In theory, this allows people to “program” at a very high level.The price point will need some work. I was poking around and calculated that a really popular app might cost you $50K-$100K/month in REST api calls. So my prediction is parts of Watson (or similar copies) will go Open Source.
Can you share the spreadsheet from the calculation?
Sorry – it was just a “guesstimate” based on their pricing model, which does scale down based on call volume.
From what I saw in a brief tour of the Watson site, nearly everything they have has long been in open source, some from IBM, e.g., the IBM Scientific Subroutine Package.There is a lot of really good open source scientific, engineering, applied math software.For optimization there is now Bixby’s Gurobi linear programming, with students of both G. Nemhauser and E. Johnson, in open source.The best direction for my Ph.D. dissertation was three words of advice from Nemhauser. Johnson was long at IBM’s Watson lab.For min cost network flows, with either W. Cunningham’s version or the quite different one from D. Bertsekas, that is also likely in open source or easy enough to program. Being able to do so well with min cost network flows is one of the best tools in the applied math tool box.Cunningham was one of my profs and since then long Chair at the world-class department at Waterloo. Bertsekas has long been at MIT.
Fred – I think this will affect personal computing much more significantly.2 trends converging – Cloud based OS + Gigabit (5G) connectivity.All your computing in the cloud basically and the prevalence of dumb terminals. Chrome book to its logical conclusion (a screen with wifi) is basically all I need for all my computing needs.With LinkNYC fully deployed in NYC (yes assuming that all cities will eventually be blanketed with Wifi capable of gigabit speeds) – I will not require a static computational device any longer.Elastic computing is going allow me to simply carry a dumb terminals ( screen + wifi ) and this will fundamentally a different platform than mobile.Paperspace.io pushing this space forwardI ranted about this here “Why this would be my last computer I ever bought” – http://www.twitlonger.com/s…
Interesting.Gonna be a long turn of evolution but pieces of that will come to pass.
Maybe it looks a bit more user friendly. Like this: http://www.monkeylearn.com/ Shameless plug since I work there, but I think that UX should be more valued. The end consumer is smart enough to experiment with AI, we just need to make it more approachable for everyone.
Chris’ post showing hardware evolution over time remind me about the solar system. With the universe we look far away to get answers. With microprocessors we go smaller and closer to biology to get answers.
AI has got quite good at doing “what we are generally good at” – this is relatively easy because we can define the features to weigh to classify representations in data.Trivial – classify pictures with a kitten in them.Harder – classify pictures where a kitten is not the main focus of attentionThis is harder because “the focus of attention” is more subjective – it is something hard to define for a human – This makes learning algorithms less scalable.I believe the big change comes when we can say – these are the techniques, these are the data sources that are available, these are the rules -Provide a robust solution assuming 10% of each are flawed.This is where small subsets of humans become truly great based on experience , such that they can handle the non-compliant cases – but often (often modestly) do not even know how they got great.What was the name of the pilot who landed a plane in the Potomac after a bird-strike a few years back. He broke “all the rules” to make a great outcome. Thats tough AI
AI has a core strength, which is ‘OUTSIDE OF PARAMETERS’ alerts.Self driving cars will always need a human to take over at some point, even if only in emergency.Learned this lesson via my wife, while she was talking to the guys who makes these things – https://www.pinterest.com/p… . Lots of people thought they would become autonomous. But, bad things happen when something like that goes of track, so drivers are still required.
I guess we nearly agreeBut *always* is a very very long time – so I cant completely agree !So – Its when you dont need flesh and blood to step in and pick up the pieces that AI really arrives.I also grant – it could be a bloody mess getting there !
We don’t agree – it will never happen.
Recent airline disasters have ocurred just at the moment you picture: autopilot giving up control and yielding to human pilots [1]. The problem is that we lose acquired abilities if we don’t practice and actually use them, the same way we forgot phone numbers by storing them in the phone.[1] Our Robots, Ourselves – Robotics and the Myths of Autonomy – David A. Mindell – Chapter 3, Air. (ISBN 978-0-525-42697-4)
“Classify” a picture your wife will like as a framed print over the living room sofa!
Ha – AI probably has me beat at that already – some things were ever beyond the wit of man !There is subjective and then there is “anyone’s guess” !
I was mentioning my work, and I refuse to say it has anything to do with AI!
The average person / business owner thinks “what am I going to do with a tidal wave of info / stuff / bullshit?” I’m going with the machinery that can make magical inferences, correlations, and presentations out of the wave.
I can’t help but wonder, what if past isn’t prologue? What if there is no next big thing?
Elia – there is always a next big thing.
Is there, though? Cars have basically been the same for 50-70 years now (to most people). Home appliances haven’t changed drastically.(Personally, I think AI will have the biggest impact as it will impact the most people and changes/fixes a lot of other technological challenges. In reality I think the biggest thing holding technology back is how hard it still is to work with it.)
It just may not be info based.Materials? Energy source – fusion?
I’m convinced that networks will always be valuable and this is just the tiniest little tip of the biggest network we have seen to date. And it’s basically ready. All the pieces are already here: IoT, bandidth, big data, elastic computing, Watson, AI, etc. etc. Maybe it won’t be one “thing”, and maybe we could consider it a sort of continuum of the “smart phone” era, but I don’t think so.
Agree with that. So much of it is still so inscrutable to most people. It’s our fault as technologists.
Perhaps the next great computing platform is truly augmented/mixed-reality. The previous computing platforms have been all operated through a 2D screen. When the screen becomes your world, i think that will revolutionize so many things, and that is what will bring together AI (computer vision and natural language via holographic assistance) together with the real world. Till then i think AI will be in the form of optimizing enterprise processes.The thing with IoT is that it either has to be automatic or operated. Amazon Echo shows that speaking to a physical dedicated product is different than opening your Siri to speak to it. Imagine a virtual Echo that operated through a magic leap?I honestly think the merger of all these technologies will come through an augmented/mixed-reality device such as Magic Leap
We talked about this with Rob May on Swantastic Swancast— his bet is on AI via chat interfaces– awesome discussion:https://soundcloud.com/swan…
that link didn’t show. i didn’t know you had a podcast. cool. will go to it.
Thanks boss. Need u on…Bitcoin knowledge bomb
anytime….blockchain too 🙂
save the debate for the studio! 🙂
Enjoyed the show, added it to the playlist. Thanks Andy!
how did i not know about the “swancast” ?instant follow
Still getting our sea-legs. Incredible conversations though!
Very cool.Become a huge fan of podcasts.
you ignore the power of your magnet
I think AI will help tackle two fundamental problems that exist with regard to large, complex data sets: 1) How to make them actionable and 2) How to encourage individuals to do things that are in their best interest (save more/ eat better/ etc).You see the rise of all these apps that nudge people into healthier behaviors. But the challenges are so nuanced and complex for any individual and situation. I’ve used a few but they never really speak to my unique needs and desires. The reality is that changing oneself to live a more efficient, healthy, robust life is something that everybody and anybody can want. And once they are inspired to want these things they are thankful that they have been convinced to want them. It might mean eating better, meditating more, saving more money, etc.So, if you ask me, there is an untapped market of hundreds of millions of people that will benefit and be thankful for being nudged into a better, more fulfilling life. I think it is something only an AI will be poised to solve on a large scale.Again, I believe it’s a matter of making data actionable and encouraging individuals to do things that are in the best interest based on the data.Am I onto something or blowing smoke?
I read something recently about this also being the end for “middle management”. AI, algorithms, and big data will be driving the decisions of lower level workers, who will be measured in order to improve the AI and efficiency. So there’s that side of AI driving behavior as well.
http://www.wilson.com/x/bas… I would have loved something like this back in the day. I can foresee sensors in shoes and uniforms to help give players feedback on movement and positioning.
there’s a lot of big frontiers, but i think eyeballs might be the biggest because of the gateway to virtual reality. this means glasses and contacts in the beginning, but eventually the human body. we already see this oculus, google glass, video game headsets, and all that stuff. the interface hasn’t been nailed yet, but it’s only a matter of time.
Not to get buzzwordy on you but microservices will become a fundamentally core component of building the intelligent mesh of computing that can make sense of the world we’re moving to. I whole heartedly believe the evolution of the compute layer moves to the ease in development and managed of distributed systems. AWS and cloud computing has solidified the infrastructure and “power” layer. Next we need to think about globally available services that can process and make sense of all this data. Once that layer has then been established over the next decade, we can move on to using that to power AI at unlimited scale. Where models are incredibly to run on anything beyond a single machine for the average developer right now, in the future microservices, distributed systems, will provide them with an easy way to get scale for free.Why do I believe all these things? 1. Because I’m building it. 2. Because I’ve seen it while working at Google. Google is at any given time, a decade ahead of the entire world. Cloud compute, container orchestration, docker, kubernetes, all these things, they’d done it a decade before it appeared in the public tech space. Now they’re openly talking about AI. They have the compute platform which gives them unlimited scale to power deep learning. They have compute, microservices, etc. I’m year 1 into a decade long journey to build the next AWS, globally distributed systems and then onto the generic unsupervised AI platform.Would love to chat more with anyone who’s thinking along the same lines.https://micro-services.co
I think along the same lines, but I’m in the choir and you already know that :-)With a little luck business people will pay attention to genuinely interesting things instead of the next fad.
I watched a lot of this unfold first hand while at Netflix (using AWS). Wholeheartedly agree that microservices are the future, but it’s sometimes easy to forget that this is not obvious to many outside the Valley.Although I’m somewhat of the mind that most of the major pieces exist today and are available via AWS, Google, Docker, etc. Much value to mine from reorienting product organizations around DevOps. Wondering what I’m missing re: building a new IaaS platform? Unless you’re a layer above and doing DevOps-as-a-Service?
So I don’t live in the valley, I live in London and I’ll say from a global standpoint, organisations and engineers everywhere are aware of distributed systems, microservices and the leverage it provides. Quite honestly its the organic path to scale and everyone, absolutely everyone who ends up scaling an organisation has to go down this path whether they call it SOA, distributed systems, microservices or anything else.I worked at Google and then Hailo. At Google I saw the future and at Hailo I helped build it. Back in 2013, Netflix was really the only company openly talking about microservices so we used you guys as a model for our own global microservices platform on AWS. We leveraged Cassandra, Zookeeper, RabbitMQ, NSQ and then built absolutely everything else from scratch in Go. The tools just didn’t exist. While the infrastructure layer is improving and we’re moving up the stack with container orchestration systems like Kubernetes, it still takes an engineering team of experts to build, automate and then maintain that kind of platform at scale. And here we’re only talking about the infrastructure side.The platform capabilities for running microservices extends much farther; service discovery, monitoring, routing, dynamic configuration, distributed tracing, metrics, logging, etc, etc. Not to mention the client libraries actually enabling developers to write microservices that tap into the platform without having to think about all these distributed systems.The next layer is essentially microservices platform as a service. Think about what’s internally available to developers at Netflix, Google, Twitter, Facebook, Uber, Hailo. A fully managed runtime with libraries that allow you to leverage that without having to worry about the details. While all the tools exist for people to compose their own platform, there’s no cohesive whole system. I’m seeing this issue amongst all the companies I’m speaking to and there’s definitely going to be a need for Distributed Systems as a Service.It’s going to be a while before we get there though. In the meantime companies will continue to build their own platforms but still need the tools to build and manage microservices without writing their own frameworks from scratch. It’s what I’m working on now https://github.com/micro/micro.
Very, very cool. Sounds like a good plan, I definitely see the need. A former colleague of mine is building CloudNative.io based on the Netflix model, starting from a different direction I believe. Might be worth checking out. I’ll hope to use you guys down the road!
One of the things that’s interesting to me about your point is that b/c we’ve moved so heavily into consolidated databases, much of the data itself has lost it’s locational relevance. Attributing a bunch of characteristics (long/lat, smart devices measuring rivers rising, etc.) into a centralized database doesn’t negate that fact. I’m very curious to see how distributed systems re-balance meaning and relationships in the physical, technical world. I bet it’s going to be way more world alterting than the IoT hyperbole we’re hearing about now.
Question to contributor(s):We had a discussion with a Physist this morning and one interesting thought he offered that we needed smarter people than ourselves to provide an opinion on.The Physist said one thing that worries him is that the human race concentrates on inventions that make us more money and don’t invest in the inventions to keep us humans alive. He therorizes a pandemic coming out of Asia Pacific where animals and humans interact (We thought Africa) that will be resistant to known cures killing millions. Do any contributors in science and medicine see anything others can’t see yet? Thanks in advance.
there are a number of antibiotics being developed from dirt (where most unknown bacterium and viruses and molds live) that are being tested and weeded through. Anything that seems like it could work in a human without killing us will probably start a fasttrack development process and approval process by the FDA because of issues involving antibiotics
We had confidence the response would come from one of the many erudite females.Thanks!
Google Glass was the Newton of today. I suspect that the next thing will be like glass, but done like the sensibilities that brought us the iPhone.
My take away: bugs are gonna get weird.
Ha! Indeed. “Shit, why does my car keep taking me to KFC? I’m a vegan!”
I think the main challenge is going to be UI.The next generation of mobile chips designed by ARM (in phones end of this year -> 2017) will be more powerful than todays most powerful gaming platforms (eg PS4).(eg http://www.computerworld.co…So the phone in your pocket is a supercomputer. But how to unlock it? How to make this massive power available in easy to use ways?Voice is important as is AI to ease interactions.And so is VR and AR.VR would seem the most natural next step for gaming and will definitely find a foothold there, maybe a huge foothold, but we are on a learning curve with respect to the matter of environmental vertigo and a VR headset is a special purpose device not suitable for ubiquitous usage.AR is potentially extremely interesting and can be ubiquitous. It doesn’t replace reality as does VR, it augments reality and hence can provide AI enhanced day to day reality. Coupled with voice this can be extremely powerful. Google glass is an early version but we have to have very lightweight versions and the ideal is contacts.The mobile phone form factor has conquered laptops and tablets. But it has its limits and those need busting.
THis is important, but 99.99% of these things won’t have any UI at all. They will “just work”. Turn it on, it gets its IPV6 address, and then it just starts pumping sensor data to services somewhere else.
You’re absolutely right that iOt will result in a gigantic explosion of data from ubiquitous sensors. And I agree that some things will indeed ‘just work’ (we hope). A good example is the Marathon washer drier that has practically no controls. But there will be a huge amount of content and interaction that will demand our attention and the efficiency of that will be a significant design concern that will influence the way we relate to compute power.
So true.
The next compute cycle will develop out of inter-network and inter-app settlements that recognize that value in networks inherently gravitates to the core and top. A winner takes all model (settlement-free peering between silos) isn’t sustainable given rapid supply obsolescence and incredible demand growth and divergence.Settlements serving as price signals between actors provide incentives and disincentives which clear supply and demand ex ante at the margin. Balanced “inter-network” settlements north-south and east-west also act to convey value and coordinate end-point upgrades such that access is uniformly available and inexpensive; countering the growing digital divide.Ultimately this model is the best way to relate or directly tie in the underlying communication cost to the socio-economic session/transaction for all these technological ecosystems people are forecasting (IoT, VR/AI/AV, 4K & 2-way video), but have no clear-cut path to sustainable economic reality.
Here at MWC in Barcelona, there is a huge noticeable jump in focus this year to AI, IoT, and to a lesser extent VR (VR was bigger here last year, and I somewhat agree with Fred that it’s taking a bit longer to overwhelm).Zuck just spoke and said how much FB is redirecting tons of engineering effort towards AI– I see this as a potentially big innovation source to watch (an upcoming #2 to Google?)And at the Samsung product launch last night, (where he also spoke about AI and VR) they handed us all Oculus goggles to keep.
Never easy to predict the future, but always fun to learn from the patterns of the past, and it looks like generations of disruptive Platforms also sway back and forth between aggregation and disaggregation, and between server side and client side empowerment…and interestingly enough, they tend to rely on the previous generation Platform but disrupt the one before. I posted some more thoughts here:https://medium.com/@salmanf…
Noticed some comments dissing Voice Rec/Trans. This has really come a long way. We are just in the realm of realizing the difference between 96-97-98.8% accuracy. We will get a long way over the next 5 yrs. with the “meaning/phrasing”, just a matter of ML moving into faster learning (learn/retain>hypothesis re what is retained to use to move forward one frame/step).Using the Steve Jobs analogy, it is a matter of somewhere around 2018-19 where things can become ‘cool’ in development. The voice for Siri sucks. Google could have stuck with just delivering the answer, but wanted to get into voice. So we will have to get past the ‘not as good as it could be’ realm and move into where development can be performed by people who truly know what would explode.Also remember the simultaneous attempts at Telepathic Rec/Trans. Thought about that this morning when seeing a headline re Sony and AI in Your Ear.No matter what, those who know what they’re doing whether it’s on tech/audio/visual will start to rise to the top and the VA will become something useful and comfortable. https://www.youtube.com/wat…
These epoch discussions are always fun. At school in the late 90s, me and my music obsessed mates would start a discussion with: “57 = rock’n’roll, 67 = psychedelia, 77 = punk, 87 = house/techno, 97 =….” and we waited and waited and (forgive us for not including hiphop) nothing new came. Well, the internet came, and made all music from all times instantly accessible to everyone and so all future music became a melange of many references from the past. There’s no way i believe we’re there in tech… but, for fun, it is worth thinking about.
There is some value in what Dixon wrote, but mostly Dixon is not seeing computing or information technology clearly.Good News 1:Some of what he mentioned will get some sales.Good News 2:Relatively straightforward exploitation of some or all of cheap computers, say, $1 each, the cloud, smartphone sensors, the Internet of things (IoT), and drones should result in some useful solutions for some narrowly focused problems.Bad News 1:Dixon is seeing too much in current computer technology. He’s like a kid who just left a magic show and believes in canceling gravity. Nope: The usual laws of physics are still just the same; what the kid saw violates no laws of physics; and the impression otherwise is just trickery.Crucial Point 1:There is a lot there that is good and new, however, the good is mostly not very new and the new, mostly not very good.E.g., from Fred’s link to the IBM Watson site, some of that is decades old material from statistics and operations research. E.g., they have multi-objective optimization. Right: I’ve been there, done that, got the T-shirt — e.g., J. Cohon’s course on multi-objective optimization.There’s a practical point about that material: Successful applications tend to be for relatively static, quite narrow problems — that is, practical applications — selected quite carefully.Hype Warning — Be CarefulHere there be monsters — hype: There is a danger of being taken in by the hype. Or maybe an opportunity to take in others with the hype — same coin, other side?E.g., the image recognition is for a limited collection of images carefully described in advance. For the US military wanting image processing to find, e.g., Russian T-72 tanks or the Sukhoi Su-35 — maybe interesting.The various cases of the data processing don’t effectively connect with actual thinking, cognition. Fundamentally the thinking is hardly better than what can see at a trained dog or cat act.Dixon writes:Extrapolating into the future: We can try to understand and predict the product cycle by studying the past and extrapolating into the future. Yes, can do that, but looking at the products is too indirect. We don’t do design by looking just at earlier finished products and “extrapolating”. Instead, we look at the fundamentals from the math, physics, chemistry, engineering, materials, etc. and then see what we can design.Monitoring distributed systems: Distributed systems is one good example. As the number of devices has grown exponentially, it has become increasingly important to 1) parallelize tasks across multiple machines 2) communicate and coordinate among devices….IoT will also be adopted in business contexts. For example, devices with sensors and network connections are extremely useful for monitoring industrial equipment. Yup.So, how to do that? The workhorse of monitoring has been thresholds, and the pains in the back side have been high false alarm rates and low detection rates. Now, if Chris would like to talk …!Right, with enough data, we know just what to do — use the Neyman-Pearson best possible (forever) result, right, from about 1947 or so, not nearly new.But Neyman-Pearson asks for more data than usually we can have in such monitoring so we need to do well with less data. Right. Now if Chris would like to talk …!Why? Because, as Chris described, the systems to be monitored are getting more complicated. They are so complicated that even with big data we can’t hope to have much data on all the possible failures or how to detect, diagnose, and correct them. That is, with the complexity, the number of failures has outgrown our historical data to describe them. Can something be done, about detection rate and false alarm rate? Yup.Would Chris be interested? I seriously doubt it!Marching forward: But the future is coming: markets go up and down, and excitement ebbs and flows, but computing technology marches steadily forward. “Computing technology” is not the main driver or issue. For the changes Chris is talking about, the main issue is just some original applied math. In the terms of the first movie Indiana Jones, Chris is “digging in the wrong place”.Talking original math to the Silicon Valley VC community is a grand, new definition of hopeless. Flip side: Silicon Valley has lot more in hen’s teeth than entrepreneurs with such math abilities. Someone with a good application stands to have next to nothing in competition!Why the math? Because what we are talking about here is (1) taking in data, (2) manipulating the data, and (3) reporting results. The results are supposed to be valuable as information. E.g., identify an object, steer a vehicle, inspect a remote component, target some ads, diagnose a fault, design a process, etc.So, the technical core of the work is the data manipulation. For that we can use:(1) Manual Methods.Program what people have long done manually or, now, understand in principle how to do manually.(2) Off the Shelf Methods.Use, say, logistic regression, factor analysis, support vector machines, classification and regression trees, random forest classifiers, cross-tabulation, power spectral estimation, Wiener filtering, Markov process simulation, experimental design and analysis of variance, etc.(3) Intuitive Heuristics.Guess, think intuitively, guess again, and quit when tired. E.g., simulated annealing, genetic algorithms, empirical fitting to data, possibly with ad hoc modifications.(4) Math.Start with reasonable assumptions about the real situation. Use those assumptions as hypotheses in theorems. Use the conclusions of the theorems to say how to manipulate the data. In some cases the theorems can say that we have the most valuable results possible; that can be good for the value of the results but also for knowing when to stop looking for better means of data manipulation.Also theorems and proofs are by a wide margin the highest quality knowledge in our civilization.E.g., the recent LIGO experiment was just awash in a lot of quite carefully done applied math.E.g., if the input data really is a second order stationary stochastic process, then find the power spectra of the signal and that of the noise and use a linear filter to separate them to the best extent possible (optimal). Maybe do the arithmetic with the fast Fourier transform. Maybe use the results to decide where to drill for oil — possibly valuable results.Always Look for the Hidden AgendaAnd in this case, my guess is that Chris is looking for deal flow at a16z. For that, I can’t believe that he cares about any of the stuff in his article and, instead, cares only about the usual:A young company, with 2-5 founders, with (A) a product/service, with some use of information technology, (B) for obviously a huge market, (C) with traction significantly high and growing very rapidly, and (D) eager to sign a term sheet with onerous terms for an equity investment of $10 million to $50 million for about 1/3rd of the company and BoD control.Then Chris believes in a Markov assumption: (i) The technology, as discussed in the article, of the company and (ii) the financial future of the company are conditionally independent given (A)-(D). So, given (A)-(D), just f’get about (i). And with just (i), f’get about an investment.So, the real agenda of the article is not about technology or “The Future of Computing” but about deal flow with traction in a huge market.For me:Gee, with T-SQL, just learned thatTRUNCATE TABLE main_table;fails with a message that the table main_table is not found or that don’t have sufficient permissions to do the truncate operation. Both claims are wrong!So, since the table main_table clearly exists, go chasing down all the security issues in SQL Server, which is a lot of stuff, nearly all of it essentially just applications of some very old ideas in capabilities, access control lists, and authentication but explained with B- grade technical writing. Look at dozens of Web pages. Dig into a book of about 1000 pages.But, guess, try, and discover:USING Schema_101;TRUNCATE TABLE main_table;works. AndTRUNCATE TABLE Schema_101.dbo.main_table;works. The table does exist, and permissions had nothing to do with it. The main issue was just poor documentation of the syntax and semantics from poor technical writing.Ah, now onto loading a good, first batch of initial data into my database and end to end testing the software!Biggest bottleneck in the future of computing: Really bad technical writing. No joke.
wow. all I can say is that I hope Chris sees your comment here, since you have invested as much effort as he did writing his post. sorry I don’t have anything better to add, I should read again in the morning.
‘the good is mostly not very new and the new, mostly not very good.’ he, heI have seen a Watson demo and the language used by the presenter to describe what the machine is doing was full of embarrassing hyperboles. I would have preferred saving the AI label for something truly magic, I also think it is rather misleading. everything around us is still 100% the result of human intelligence.p.s. I don’t believe in the IoT, not beyond the importance a souvenir would have for me for only a few weeks after I have visited a place. Time will ruthlessly select the ‘priviledged’ hardware and software that will become a permanent addition to our lives
Maybe the IoT hype is for consumers so mentions consumer applications. Right, these are not more exciting than a Barbie doll with a battery, say, to make her eyes light up — sick-o!But IMHO the main role of IoT is business, industrial, government, and national security remote monitoring and control.E.g., before the Internet became popular, GM was so interested in such things that they worked out an architecture comparable in complexity with, say, the Internet, JASON, XML, etc.Now for such things, just use common off the shelf (COTS) products and the Internet. So, I suspect that GM will be or is making good use of IoT, and Ford, Amazon, FedEx, American Airlines, American Electric Power, Exxon-Mobil, GE, really, essentially all the larger industrial companies.From the IoT opportunities for new data and new points of control, I sense a broad range of applications of stochastic optimal control. I doubt that there are even a dozen entrepreneurs in Silicon Valley or even 1 VC in Silicon Valley who could give a good explanation of just what stochastic optimal control is and it’s potential for monitoring and control for industry. Chris didn’t mention stochastic optimal control. Hmm ….Disclosure: I wrote my Ph.D. dissertation in stochastic optimal control. As part of that, I gave a graduate seminar on the topic. Soon, another grad student, with the same adviser, wrote his dissertation also on that topic. Our adviser was J. Cohon, later long President at CMU.For my effort, I got going on that work before I entered grad school, and part of my direction was three words of advice from G. Nemhauser, now long at Georgia Tech.Stochastic optimal control is on the shelves of the research libraries, and now current computing and IoT enable some valuable applications. So, that should be counted as part of “The Future of Computing”.Sure, the bad news is that to the startup community, stochastic optimal control is of less interest than some chunk of ice on a moon of Pluto. Disaster. But, sure, the flip side is an opportunity — e.g., next to no competition.Stochastic optimal control is a joke, nonsense? Nope: It’s some of the most serious pure and applied math on the shelves of the research libraries.Similarly for my work in monitoring.Similarly for my work for my current startup.Gee, as of last night, all my software for putting initial data into the database appears to have worked! Some of that software was intricate and used much of the original, crucial core, applied math of my project, and it appeared to work flawlessly once I got past the trivial issue of getting the input options correct! My usual approach to input options for a program is a simple text file with a dirt simple syntax — character string key-value pairs with documentation (I’m big on documentation) comment lines starting with ‘*’. So, last night typed in some comments, got dinner, omitted the comment delimiter, and got an output file in the wrong directory with the wrong file name! Fixed that, and everything worked!Then SQL started to look nice like it should: A short SQL file, and, presto, bingo, got to see the results in the database! They looked fine!Now to see if the Web site makes correct use of that initial data! That’s for today!Then on to more initial data from the same software, maybe also today. Check again that the Web site does the right things with the data. Then load more data. Tweak anything that looks bad. Maybe then private alpha test! Tweak again? Then beta test!Then go live, with a dedicated server, a static IP address, a domain name, a trademark, a tax ID, …, the Microsoft Bizspark program for high end versions of Windows Server, SQL Server, and IIS, publicity, users, ads, and revenue!From some back of the envelope estimates, if the first server, in a mid tower case at my left knee, stays on average half busy 24 x 7, then I’ll have a lifestyle business!E.g., for some of the back of the envelope, if I send, on average 24 x 7, 40 ads a second, which with my relatively efficient software one mid-tower case server and the slowest static IP address upload data rate should be able to do, and take the KPCB M. Meeker data of $2 revenue per 1000 ads displayed, then the monthly revenue would be2 * 40 * 3600 * 24 * 30 / 1000 = 207,360dollars.From some more dirt simple arithmetic, the 24 x 7 average upload data rate should be about 3.2 million bits per second (Mbps) — trivial.Welcome lifestyle business!
yes, I was referring to IoT for consumers and every time I see the media hype I think to myself people choose to ignore the data on adoption (yes, when starting from 0 for a new product, any number will be >, but that doesn’t make it the new toilet paper). They are in my view ‘toys of the moment’ and I can’t even think of a gadget of this moment in 2016 (sure, some will come and go as before). Agree with your view on the the other categories of use
.A lot of what we see as progress is just going to be convergence — everything converging on better and better standards.As an example, when you add a laptop to a network, it will recognize the “peripherals” on that network. In the last few years, that list of peripherals has begun to include all of your monitors (television) even though you may be required to add a Chromecast device.Now, you can buy a television that is WiFi connectable making even that Chromecast device unnecessary.Soon, your HVAC controls, your pool equipment, your hot water system, your irrigation system, your garage door system, your appliances, your home security system, your in house video (baby monitor) systems, your car, your body, your children will all be peripherals to that same system.At the same time, they will be collecting gobs more data (irrigation flows being determined by ground moisture content) and driving your decisions (stock up on gasoline and orange juice, Dave) and touching places never touched before (the baby has a slight temperature and has for the last hour).All of this tech exists right now. It is the convergence of letting it and making it talk to each other — really to the central brain — which is awaiting implementation.There is a Moore’s Law type curve at work here. The rate of change is going to be accelerating making this one of the best times to be alive in the history of the world.JLMwww.themusingsofthebigredca…
“It is the convergence of letting it and making it talk to each other — really to the central brain — which is awaiting implementation.”Need settlement exchanges that don’t exist outside of ad networks; 80% dominated by 3 companies. And when it comes to IoT, privacy is going to be a much bigger deal than with social media, so don’t look at ad monetization. The other 2 verticals that scale the internet are eCommerce (60% Amazon) and private/hybrid enterprise clouds. Subscription models are making slow comeback. But the latter 3 are all siloed. Everything’s a silo. So not sure how all the pieces talk to each other without settlements acting as incentives (and disincentives).
.Just thinking out loud here — I think it is going to be driven by hyper local mini networks that may or may not use the Internet or may use it sparingly as a communication pipe.Using the home/life automation I sketched out as an example, the smartphone may be the brain. It is already well underway with home security.I can alreasy use a smartphone to turn my lights and HVAC on and off.Now if the refrigerator would tell me I need OJ.JLMwww.themusingsofthebigredca…
Agreed on all those things.But how do you get those hyper local networks or standalone sensors to be easily, securely and transparently used by many different actors? This is necessary because:1) everything obsoletes quickly and someone needs to amortize the cost/risk;2) you want the system to scale across silos to be generative so the ecosystem is sustainable and technology/service doesn’t ossify (like taking 20 years to get to 15% penetration of IPv6)3) you want to ensure universally inexpensive service/access; aka reduce or reverse the growing digital divide.The resulting pricing will reflect lower marginal cost ex ante; not average higher cost ex post as with today’s ISPs (edge access). I know you are amazed by your mobile hotspots from GM/AT&T, but frankly the service cost is too high for 50-60% of the population and it could easily have been done years ago with the technology and networks.That’s just one example of markets gone awry due to poor policy and lack of inter-networking settlements. Note: I’ve been following this sector for 26 years and pretty much been surfing the “digital compute” wave for 38 years. And one last thing, I agree with your statement about convergence. But it is convergence of supply. As much as we’ve seen that with 4 major networks and service models converging (with the guys at the core and top coming out on top), we’ve seen enormous demand “divergence”. Solving for both simultaneously is tough. That’s why 95% of the players aren’t really making money as they should be in a time of growth and prosperity. The result is all the news at MWC16 in Barcelona is about technology that may happen in 5 years. If you’re a shareholder, what are you doing for the next 4 years?
Good post, covers interesting trends, but…meh. The OP is smart and covers all the right bases, and lot’s of good incremental extrapolation of current trends, but strikes me as another TLA/buzzword recitation. What would be *really* interesting is how we are going to get past two road-blocks to truly innovative change – a new dynamic for creation of secure, robust, and intuitive software (think 1970/1980s 4GL), and (most important) acceptance of a shared vision of “work” and economics once we’ve worked thru the disruption from productivity increases via automation.Having written software, and been involved with the software industry from the 1970s I actually think the state of software has been in a period of stagnation for a couple of decades. Oh yes, we have “new” programming languages, but they are essentially smallish tweaks, of existing paradigms. Moore’s law has allowed software/bloatware to skate along, but once we lose that cheat, it’s going to get ugly.
As far as the links go, none of them have to be good now (they all are). They need to iteratively improve based on new data.The algorithm that guarantees an infinitesimal improvement per iteration is good enough to eventually deliver at any fidelity, whatever it gets better at.One such algorithm is life, more specifically evolution. Organisms not only get better at surviving, you get cool stuff like diversity and complexity.It’s fun to guess at what will be the next big thing, maybe it’s fun to try and build/catalyze it too. Maybe it’s inevitable.
Spark is the analytics OS for decentralized analytics : http://www.robdthomas.com/2…
Errr, I guess my statement would be, what kind of beer do you like, ales, sour beer of some sort, lagers, something else?That question requires beer, lots of homebrewed beer
yep… love Chris’s post as well!
What is the next big thing no one pays attention too that we use everyday?WiFiUW engineers achieve Wi-Fi at 10,000 times lower power.http://www.washington.edu/n…