Using Your Data To Make Your Product Better
One of my favorite uses of AI is to use the data in your product to make your product better. I am talking about making a better UI using AI on your data.
Our portfolio company Quizlet did just that and wrote about it here.
They used the ~150mm study sets that their users have put into Quizlet over the last ~12 years to predict suggested definitions during the create study set mode.
Here is what it looks like.
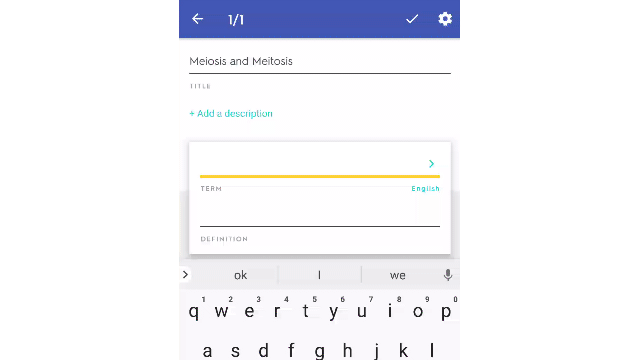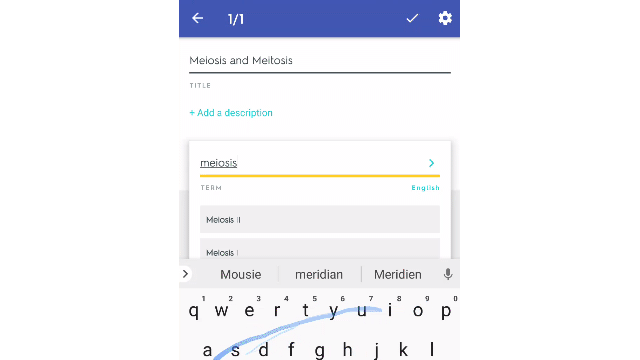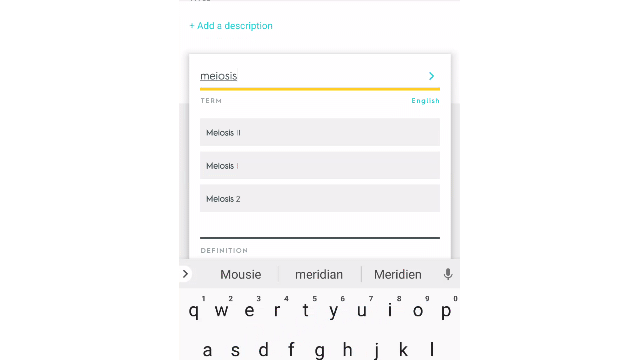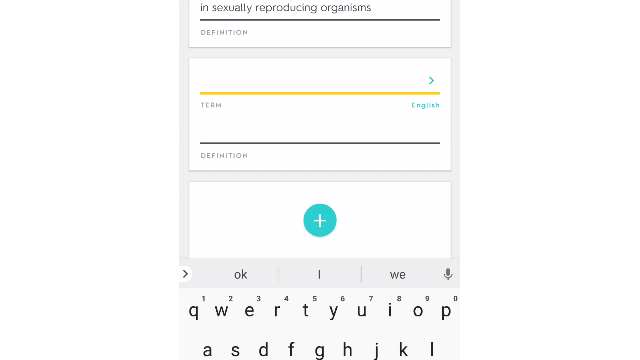
I think this is super cool and a great way to make your product better.
Comments (Archived):
Using YOUR data…yeah, that’s cool…unless it’s MY data and an invasion of privacy.
At the hacking event we hosted yesterday this exact point came up. What’s the cost/opportunity cost of security? How deep can a company go-a country go, a parent go? No easy answer there.
.Privacy is extinct and has been for a decade. It will get worse and it will never get better.JLMwww.themusingsofthebigredca…
What should be happening is that people are given the choice to “opt-in” to have their data used. (Which probably did not happen in this case.) Large social companies are using your information to make big money. But the enforcement of this is just silly. The EU fined Facebook 150,000 euros. What a joke.https://www.nytimes.com/201…
yes. but google has been using our date for years to make search, mail, etc better. how do you feel about that?the data quizlet uses is more like a public commons (like wikipedia)
I think Google is fairly upfront with letting me know that they’re using my data to make my experience better. And the Quizlet use is aggregate data to make for better results for all. What I was originally referring to, based on the post title, was ad tech amassing user data without transparency. GDPR and other privacy directives in EU will be a shock to that system.
every company needs to super-charge its primary systems of engagement with systems of insight that can make the former better and smarter by exposing real time APIs for intelligence. The budgets and funding allocation for systems of insight are approaching that of the budgets for systems of engagement. It is a really big deal.
Machine Learning is the symbiotic feedback mechanism for A/B testing on UX side and has been for a long time.
yes, it is. It can impact a lot more than UX, depending on how narrow or expansive is one’s definition of UX. They can drive product recommendations, pricing, content, and everything else.
Oh, I know this VERY VERY WELL INDEEDY, :*).The issue is that, at the moment, we’re in this situation:A/B testing algorithms = times table.ML algorithms = algebra with some prob+stats and electronics.Insights & product+content recommendations = machines would need to be able to do Natural Language Understanding — which they can’t and AI researchers are nowhere close.* https://www.technologyrevie…Whole new fields of maths would have to be invented since language is both subjective and objective and the Scientific Method of Descartes and everything after (and before) him can’t deal with this.Ah, the things Twain knows and has knitted whilst AI researchers haven’t yet picked up the yarn and started untangling the knots yet.LOL.
Yes, I agree. But there has been substantial progress over the last 4-6 years both on the consumer internet and the enterprise in terms of using A/B testing and ML to successfully personalize the customer experience. These do not use any type of NLP/NLU, but just structured data emanating from user engagement. Google filtering search terms dynamically, “Who You May Know” on Facebook or Linkedin, personalized timeline or newsfeed, personalized content and product recommendations on retail sites, predictive maintenance for machines, etc. are all great examples.But yes, there are a broader set of use cases that do involve a higher level of understanding and interpretation and we have barely touched the surface of what is possible.BTW, I love your third person referrals!
Training the data to improve products and insights is a form of market surveying with Machine Learning.
.Extremely high on Quizlet. One of the best bits of tech I have ever used. It is a learning tool as indispensable as a Big Chief Tablet of yore.I used it studying for my instrument pilot’s license. I gave my notes to others and it was incredible study prep. I made 100% on my exam.Real world benefit. No bitcoin was hurt in the transaction.JLMwww.themusingsofthebigredca…
Haha….One day Mr William M. is gonna surprise you and tell you that your breakfast was made of bitcoin (or something like that)….it’s gonna be a big day on ol’ AVC when that happens 😉
.You know I am rooting for bitcoin. I am rooting for Wm who has become the God of the Coin.I love his book. If you haven’t read it, get one. Get him to autograph it. He wrote a very nice comment in mine.I even predicted bitcoin would kiss $2100 per bit in 2017. I laid three wagers on the fact.http://themusingsofthebigre…I am a skeptic in the short term.I just hope Wm doesn’t make me eat shit when bitcoin shows up for breakfast.When bitcoin finds its killer app, I will push a peanut up Congress Avenue with my nose while naked. Live streamed. [Congress Avenue stretches from Town Lake to the Capitol in the ATX. It goes uphill from the river.]Until then, skeptic. Not opponent, skeptic.JLMwww.themusingsofthebigredca…
Wm is God of Ethereum not bitcoin?
.Could be just a Princeling?JLMwww.themusingsofthebigredca…
If there is a God of Ethereum it would be Vitalik since he owns the code and had the unilateral decision-making powers to fork Ethereum after the DAO issue.Princes tend to inherit the Kingdom arising from ascension rights.Whoever is also a core coder of Ethereum would be a Princeling.
.Over regulation and rulemaking is a drag on things.JLMwww.themusingsofthebigredca…
As I suspected – which is why i felt i could make that joke in the first place. Rooting for Wm and the various cryptos myself. And breakfast. I always root for breakfast.
.Breakfast is a big winner. Long breakfast.JLMwww.themusingsofthebigredca…
Breakfast made from Ether not bitcoins since Wm is associated with the first.
.Pretty sure he’s ambidextrous.JLMwww.themusingsofthebigredca…
Nice. Any idea what tool they used to build the model? We want to do something similar with our security app, but we don’t have much in-house AI experience.
I know; I know; AI/ML are the solution ….Uh, might I ask, what the heck is the real problem to be solved?Pitch the ball; I’ll take a swing and maybe get a good hit.
is AI an entirely reactive technology, or does it have predictive and pre-emptive capabilities?
Yes, you can use AI/ML to help predict outcomes, predictive analytics. You can also use it to prescribe likely steps to get to a certain outcome, prescriptive analytics. We do both in our B2B sales tool clozer.ai.
AI/ML now are, for what’s actually useful in practice, essentially just old statistics. There can do as long have been able to do, descriptive statistics, exploratory data analysis (J. Tukey), cross-tabulation (quite broadly the most powerful statistical technique when have enough data), statistical hypothesis tests, statistical estimation, and statistical inference (including predictions with confidence intervals, etc.). E.g., get the full collection of multi-variate linear statistics — regression, principal components and factor analysis, analysis of variance, discriminate analysis, etc. Also get lots of cases of curve fitting, e.g., Lagrangian interpolation, least squares multi-variate spline interpolation, etc. And need to pay attention to lots of approximation results, sufficient statistics, etc. E.g., good mathematician L. Breiman (M. Loeve student at Berkeley) did some quite practical work with classification and regression trees (CART). D. Brillinger (at Berkeley, J. Tukey student at Princeton) has done a lot on time series. There’s the Box-Jenkins work.What else is in the journals of mathematical and applied statistics is astounding beyond belief. E.g., I’ve published in that literature, and what I published is quite different from the statistics I mentioned above. It could be said that the crucial core original math for my startup is in some sense statistics, but it, too, is very different from the above. Really, what I’ve done that could be called statistics is just some original applied math with some advanced prerequisites for some pressing, large practical problems.E.g., once I did some statistics for US national security: I had a continuous time, discrete state space Markov process subordinated to a Poisson process. The discrete state space was finite but from a combinatorial explosion huge beyond belief. So, I proceeded with some Monte-Carlo which worked great. Lesson: What can be done with statistics is as far as we know unlimited, limited only by what good, new ideas people can have.In addition might use some of classic, operations research mathematical programming optimization — linear, network linear, integer linear, quadratic, convex, unconstrained non-linear, e.g., Newton (not nearly new here guys but still darned powerful), quasi-Newton, conjugate gradients, constrained non-linear (Kuhn-Tucker conditions), multi-objective, deterministic dynamic, stochastic dynamic, etc. Special cases include min cost network flows, sequential testing in statistics, maximum matching, bottleneck assignment, shortest path, etc.In addition there’s much more can do with stochastic processes — analysis, characterization, simulation, filtering (e.g., Kalman, stopping times, non-linear), detection, smoothing, extrapolation, optimal control, etc.Oh, yes, for the new stuff, if you have 1+ billion pictures and label them as houses, cars, kitty cats, puppy dogs, men, women, etc., have some high end GPUs, and have a lot of patience, then you can build an image recognizer. With some specialized techniques can do some text to speech audio, some speech recognition, some progress on understanding text (simple meanings in simple text), and more — e.g., self-driving cars.Quite likely, well over 90% of what people want to do with AI/ML now would be better done with just what’s long been on the library shelves as statistics, operations research, applied math, and parts of engineering. For what’s new from AI/ML, it’d be wise essentially just to f’get about it unless have some quite specific reasons otherwise, and then will stand to be disappointed.Again, once again, yet again, over again, one more time, we have just left a long AI Winter, passed through an AI Spring of Hope, are now in an AI Hot Summer of Hype, by Turkey Day will be in another AI Fall of Failure and then into another long AI Winter.Along the way to the next AI Winter will be a lot of gullible suckers converted into road kill. Then with the suckers out of the game, we will be back to some things productive for reality.
No need for 1 billion pictures to train image recognizer.The Vicarious team showed their Generative Shape Models for image recognition of text and that only needed 1,400-ish images instead of the typical 8,000,000 for a Deep Learning Convolutional Neural Network.https://uploads.disquscdn.c…
Of course my 1+ billion pictures was frosted with contempt!Of COURSE don’t need 1+ billion pictures in the training set!Instead, just need Generative Shape Models. Lots of people know that! I didn’t know that, but again lots of people do.But, I’ve looked between my eyes and ears and so far have yet to find any Generative Shape Models, but I can read written characters just fine! And I learned to recognize a Tasmanian tiger, a killer whale, a Siamese cat, a possum, etc., each from no more than a few sightings, maybe just one!With software for anything like real intelligence, won’t need convolutional networks either!I can understand why the USPS, lots of check processors, etc. want computer handwriting recognition — they just want the stuff to recognize handwriting accurately, and to heck with the intelligent part.Here I was responding to the subject of new applications of AI/ML, and my view is that nearly always just f’get about AI/ML (if need to recognize handwriting, kitty cats, and faces, then that’s different) and use new/old applied math, statistics, operations research.E.g., at the a16z Web site on AI/ML, read that one of the applications is vehicle routing optimization. Ha!!!!! What a joke!!! Vehicle routing optimization is an old problem with many deep and powerful results, and AI/ML is not even up to the baby talk stage yet. Uh, did I mention that I was Director of Operations Research at FedEx where vehicle routing was one of my projects?E.g., the core problem for vehicle routing is the traveling salesman problem, and that is the poster boy problem for the now profound question of P versus NP, the Clay $1 million prize, etc.The results of AI/ML getting into any of the classic operations research optimization problems will be like the local junior high basketball team going up against the best of the NBA Spurs or Warriors. The AI/ML people will look like total fools, but that wouldn’t be much of a change from the present, would it?At least 99 44/100% true is AI/ML have a lot that is new and good. However the good is not new and the new, not good. Or, start shopping for heavy hat, coat, and gloves: The heat of the AI/ML hype is about to cool in the AI Fall of Failure and then move to yet another AI Winter — a really cold one. Is there a way we can short this stuff?For 99 44/100%, AI/ML are selling sizzle, and soon enough people will be asking “Where’s the beef?”.As in the AI/ML history at that a16z Web site, back to the 1950s AI/ML was a field of dreams essentially as in the IBM publicity that their computers were “Giant electronic human brains.”. It’s still a field of dreams.And since the 1950s, we’ve gone to the moon and back, gone to and explored Mars, sent probes to the planets, moons, and asteroids, including all the way out to Pluto (maybe a good place to send the AI/ML people?), put numerous fantastic telescopes in orbit, some at some of the Lagrangian points, gotten quite sure about quasars, neutron stars, black holes, gravitational waves, the 3 K background radiation, the big bang inflation, dark matter, dark energy, the strong and weak nuclear forces, the physics Standard Model, just how DNA and RNA work, sequencing both DNA and RNA, proving Fermat’s last theorem, microelectronics down to 14 nm, optical fibers sending 1 Tbps, the SR-71, the F-117, the Internet, highly polished work in linear programming, public key cryptosystems, ocean acoustics, DVDs, plant and animal breeding, curing smallpox, great progress on nearly all the more important diseases, much more efficient cars needing much less maintenance, new building materials and techniques, high bypass turbofan engines, numerical solutions of both ordinary and partial differential equations, supernova, fundamental computer algorithms (as in Knuth’s TACP), disk storage densities and prices, oil prospecting, fracking, clean air (NYC), clean water (Great Lakes), computer operating systems, document processing, plastics, materials, and more.And, then, since the 1950s, there’s AI/ML –for both new and good, still nearly only just a field of dreams.
The AI thinks this football cake is a KANGAROO.https://uploads.disquscdn.c…
Twain Twain, how many ways do we have to drive a stake into the heart of the AI/ML hype monster?I worked in AI at IBM’s Watson lab. Our real work was monitoring server farms and networks. Okay — was a big problem then and a bigger problem now. The project got started in part because some guy did some work on DEC system management using the CMU language OPS5, that is, rule based programming with a RETE network from C. Forgy.Well, okay by me, boss: Let’s do good things with system monitoring.Soon I did an up chuck when I saw that we were to use the rules to use data on performance thresholds. Bummer.Look, guys, there are two ways to be wrong, false positives and false negatives; they both have rates; we want the lowest rate of false negatives (missed detections of real problems) we can get from whatever rate of false positives (false alarms) we are willing to tolerate; we want to be able to adjust the rate of false alarms, know what rate we are requesting, and get that rate in practice. Now, if the AI/ML people had half the brain of a half wit, they’d jump on this like a wino going for an open half bottle of Thunderbird as great AI/ML.But, so far it’s not new; it’s essentially necessarily some continually applied statistical hypothesis tests with the null hypothesis that the system is healthy.Then we notice that we can get data on many relevant variables so need hypothesis tests that are multi-dimensional. And for such multi-dimensional data have no hope of knowing the probability distribution of the data under the null hypothesis so need tests that are distribution-free. Yup, there were none such in the literature. So, I did some applied math, applied probability, mathematical statistics original research and cooked up a huge collection of just such tests. I used measure theory, borrowed measure preserving from ergodic theory, saw some symmetry and borrowed group theory from abstract algebra, used the pure math result tightness of S. Ulam, had some ideas, stated and proved some apparently new theorems for the work, etc., wrote some software to implement the math, tested the ideas with some real data from a cluster at Allstate and also some really bizarre data from a simulated system, typed the paper into TeX, and published it in Information Sciences. Gave a talk on it at the main NASDAQ site in CT.So, I did some actual research, new, correct, and significant for monitoring server farms and networks and published it. Really, that was the only significant (1) piece of research and (2) progress on the real problem the group did. And, for monitoring, the work remains essentially the best in class in the world and far ahead of some work at the RAD Lab at Stanford and Berkeley of Patterson and Fox funded by Microsoft, Sun, and Google.Of course my work is way more powerful than any AI./ML approaches. My paper does say that if throw away the math and just use the results as heuristics with unknown properties, then could call the work AI/ML. That point remains, and AI/ML are STILL way behind what is in my paper.AI/ML — what a pile of horse pooie, with a few exceptions.So, again we have driven a stake in the heart of the AL/ML hype monster.The stuff in my paper; that’s an example of what we really can do. The research library shelves are awash in beautiful, powerful, deep work in pure/applied math, optimization, probability, stochastic processes, statistics, and much more. It’s a huge ocean of terrific work; AI/ML, once filter out the heuristics, hype, and sewage, is hardly a drop in that ocean.”Intelligence” — gee, you know how to ruin my dinner!Here’s an example of real intelligence: I had some bread heels on my back porch. My kitty cat was there and so was a local possum. The two were about as far apart as they could get on the porch with the bread between them. My kitty cat didn’t want the bread, but the possum did. Now for intelligence:How’d the possum know it wanted the bread? That’s not normal food for a possum. They likely prefer birds’ eggs or some such.How’d my kitty cat know to stay away from a possum, an animal with a nasty bite and maybe it saw then for the first time?How’d the possum know to avoid my kitty cat; maybe the possum had seen a cat before but likely not mine?Bet what they were using was nothing like AL/ML.Uh, my kitty cat can do the right, complicated thing in new situations. She knows what the real causes are and throws away the rest. So, she knows about causality. That’s not common yet in applied statistics — certainly not in AI/ML.Again, AI/ML wouldn’t be able to tell the difference between Newton’s celestial mechanics and the Ptolemy’s epicycles since they both can be made to fit the real data.So, a cake and a Kangaroo both fit the data of the AI/ML curve fitting. Guys, that’s just bad curve fitting.Stock up on really warm and rugged hats, coats, gloves, and boots, make sure your snow blower and emergency electric generator are working with plenty of gas for both, put aggressive snow tires on all four wheels of your four wheel drive because a long, cold AI Winter is well on the way.
Wisdom. This is why now my invention is done, I’m going to do something super “low hanging fruit”.https://uploads.disquscdn.c…
i’m overwhelmed by the generosity of your detailed reply. i will try to do it justice in the next couple of days.
CONTRIBUTORS:How do you respond when your data to make your product better gets hijacked and held for ransom? Also Bitcoin’s advocates to educate about the crypto benefiting the mainstream can’t shake being associated with criminal enterprises which could tank the price of BTC $1600 back down to earth. (Similar to what happened when Mt. Gox had a theft, hard to even make that comparison).Using Bitcoin as a currency allows no Central banking system or middle person but still maitains open verification and tracking. How is anyone able to elude the exchange of the money received and cashed without being tracked? (Hoping William Mougayar will explain it in laymans terms, reason we didn’t request Twain Twain)Who in the world is still using XP?
XP SP3 Professional? I’m using it. With the .NET Framework 4, IIS, SQL Server 2008 or some such, Office 2003, a recent copy of Firefox, the latest copy of Chrome, my favorite scripting language Open Object Rexx, my favorite programmable text editor KEdit, plenty of use of Ethernet, TCP/IP, serial async, USB, SATA, WinDVD, Windows Media Player, C, C++, C#, Visual Basic .NET, Fortran, the IBM Optimization Subroutine Library, LINPACK, Adobe Acrobat, D. Knuth’s TeX, about 200 scripts in Rexx, about 200 KEdit macros in Kexx, about 200 macros for TeX, CURL, good usage of NTBACKUP (for backup/restore of bootable partitions) and XCOPY (for the other cases of backup/restore), Microsoft’s Power Shell, NERO for writing DVDs (used to use for backup to DVDs), WinZIP, some old software for communicating over serial async (rarely need it but crucial when need it), etc..Have 24,000 programming language statements in 100,000 lines of typing I wrote with KEdit, etc. for my startup designed, running, timed, documented, with no known bugs, and being checked yet again for correctness.Yes, I have on DVD a full, legal copy of Windows 7 Professional and in time will install it and convert to it. But, then, I’ll also have to install the updates and all the other software I listed above, plus some, plus device drivers for specific pieces of hardware, etc.. Then I will have to configure the options for all that hard/software. And I should rush to do all that because …? And because …?Move to Windows 10? Sure, maybe in 10 years when they get the problems with bugs, security, ease of use, documentation, performance, privacy, backwards compatibility, systems management, etc. fixed.If it ain’t broke, then don’t fix it.
Quizlet = Awesome.
Rats…Quizlet is down, so the whole thing is hidden.
actually the website went down yesterday afternoon.but this feature is on their mobile apps and they stayed up
Seems like such a basic concept: inject data analytics and machine learning into your product and it will become infinitely better. In fact, it’s literally our elevator pitch: put new fuel into the old engine. But when you’re talking about upgrading legacy systems, the reticence to change is still outpacing the promise of improvements and so the pace of implementing this “simple idea” (even with great tech) is slowed a crawl.