Crypto On Campus
Our portfolio company Coinbase partnered with Qriously to study the adoption of blockchain and crypto on campuses around the world.
They published their findings on the Coinbase blog yesterday.
Here are some interesting findings:
Stanford, Cornell, and Penn lead the way in the number of crypto and blockchain courses offered to students.

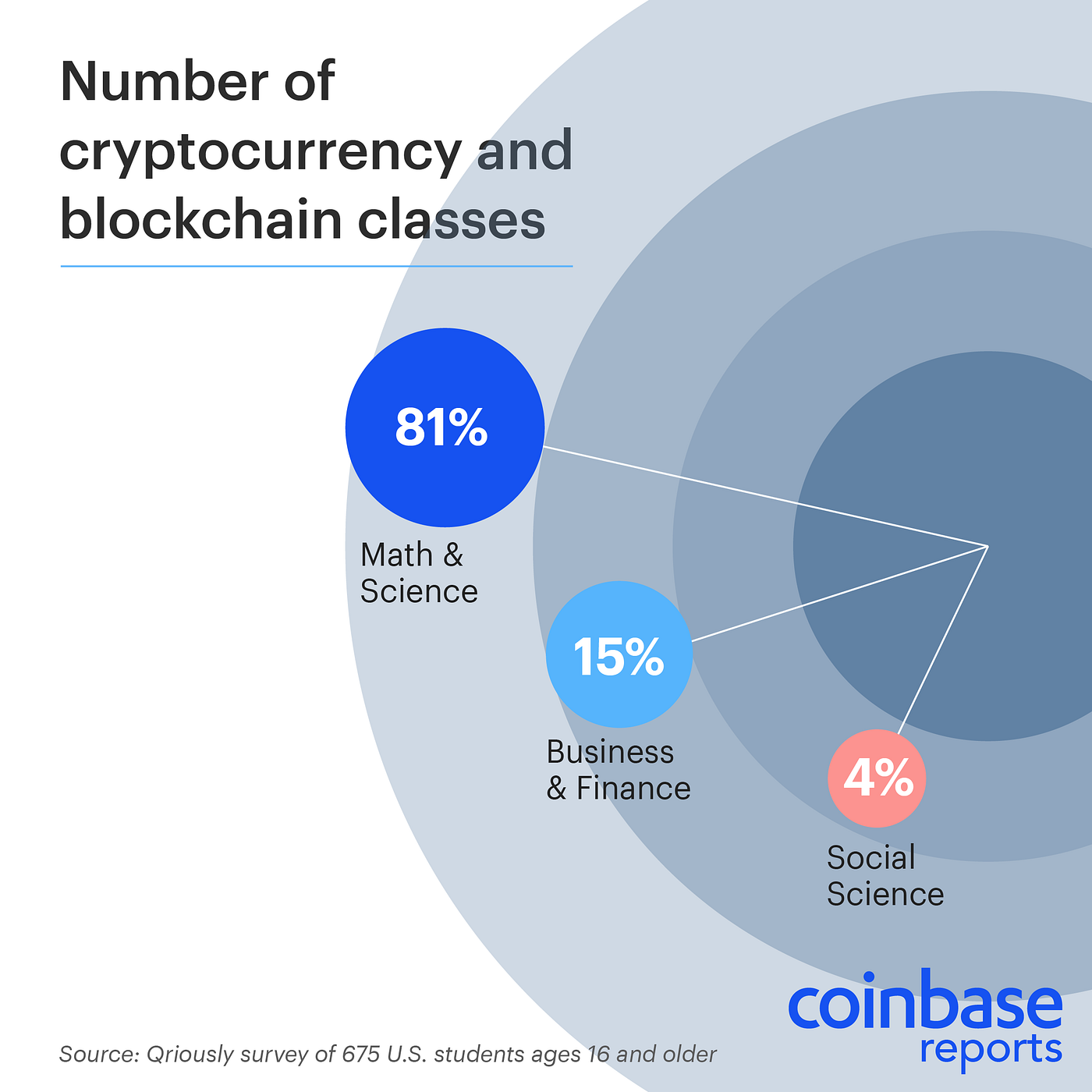
Blockchain and crypto courses are taught by math, science, business, finance, and social sciences departments.
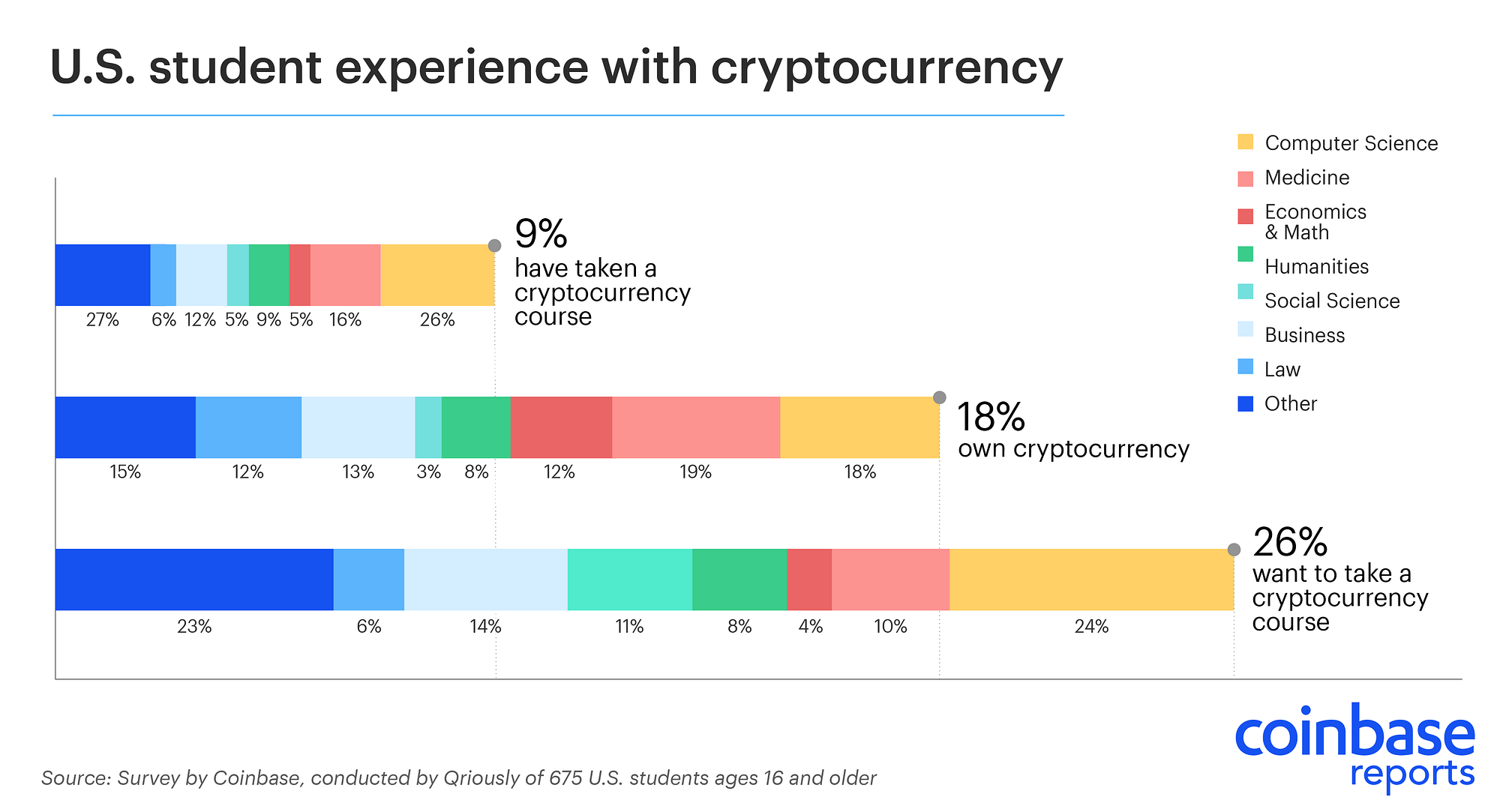
Almost 20% of surveyed students own crypto assets and 26% want to take a course on crypto.
You can read the entire report here.
Comments (Archived):
When will those schools issue their diplomas on the blockchain?Doa! Startup idea right there kids. Have at it.
I wonder what the data from Coursera and EDX reveal?
Couple of blockchain-based startups already working on it 🙂 Problem is not the idea or the technology but schools and their reluctance to adopt new protocols
The use case of a blockchain will not be the scenario of authorized writers (universities) to the chian.
For private chains it can be – public chains won’t be the only standard
BlockSheepSkin
This is very interesting and shows that we are in a clear path toward more blockchain/crypto education – which is dearly needed. But the report misses a crucial point: tertiary education has already moved beyond single courses and into full degrees. The University of Nicosia offers a full online MSc degree in Digital Currency since 2014 (https://digitalcurrency.uni…). Further, we have been issuing our diplomas on the blockchain since 2015 and in 2017 we became the first university to start doing so for ALL its degrees, using open source software (https://block.co) that has also been used by other universities for the same purpose.
Very impressive. Was this initiative pushed internally by the university or by a state program?
This has been an internal project of the university’s Institute For the Future (IFF).
What is the best accredited online certificate program?
Interesting but not quite sure about the accuracy of the data – in France we have 2 schools offering 3 courses each and they don’t seem to appear in the report…Training people, and especially developers, is key to technology adoption and improvement. Here, as well as in deep learning, tech companies have a great role to play as schools tend to be left behind / move slowly
Which schools? In French?
Yes, Mines Telecom and ECE – at least they are the 2 I’m aware of
I could swear I saw a study that said 25% of college students were ‘at risk’ problem gamblers……
An education in Survey Design/Theory is badly needed in today’s headline environment. My guess is that the surveyor asked male students in the computer science class and 50% of those likely said yes so to not appear foolish. FredCNBC
college is a financial gamble for students, but not for hedge funds and the corporate ecosystem that has grown up around the roulette wheel of modern education.
Great study which will hopefully bring even more awareness to the topic.
crypto – still seeing “capitulation”?
As an FYI, I taught a couple of lectures on blockchains in my graduate Database course in the Dept. of Computer Science at the Univ of Colorado Boulder.
Put up a web page for online blockchain courses which you can charge for. (There are already adsense ads for this and even the University of Oxford does it I just saw). [1]Or for that matter even seminars for companies or teaching by some kind of video link done personally by you (and hey maybe later some of your students).Marketing wise you could simply send some emails to the IT departments of larger companies and pick up a few clients that way. Even if you have to give away the course at first you will then later be able to charge by using those references and that experience.[1] https://getsmarter.sbs.ox.a…
Here’s a link to the last lecture I gave. It was after a bunch of technical stuff we had covered. More philosophical: http://frankwmiller.net/vid…
My niece is on that campus she just returned from some bridge building offsite in some third world country.Video: You need to send (or by way of twitter) that to Fred for video of the week. I scanned some of it and it looks interesting.
Graduate data base??? Fantastic!!Terrific!! After I start to get SQL Server installed again, I’ll come to you for:(1) How to get SQL Server installed without it being (A) broken and won’t run, (B) won’t repair, (C) won’t uninstall, (D) won’t reinstall. So, have to restore the associated bootable partition of Windows and try again this time hoping to make the poorly documented, secret, magic clicks.(2) Once I have SQL Server running, how to get it to use my old database files, .MDF and .LDF.(3) How to understand all the options in SQL Server Management Studio. In particular, how to work with logins, users, etc., possibly just via the command line program SQLCMD.!!!! :-)!!!
Sorry, this was graduate level material. Deep details on transaction processing, fault tolerance, concurrency, different kinds of databases like key-value stores and graph databases (my personal interest: https://github.com/fwmiller… ) and a slew of new systems like BigTable, Cassandra clusters, etc…
Gee, for my Web site, I wrote a key-value store! Each key is a globally unique identifier (right, GUID) to identify a user, and the value is their “session state” (as a byte array of a serialization of the instance of a class I have for their “state”).In the code, I used two instances of the standard Microsoft .NET collection class. One instance takes the key and value and uses them, respectively, as the key and value in the collection class. The other collection class is the same but has as the values the time of the most recent user activity — so can know when to do a session time out and delete the user’s key and value from other instance of the collection class.Hopefully this Microsoft .NET class uses either AVL trees (Knuth, “Sorting and Searching”) or red-black trees (Sedgwick?).The data communications from the code in the Web servers to the session state store is just old TCP/IP sockets.”Concurrency”? Right! It’s an issue. Okay, I’m willing to try keep it simple and be quick and dirty! So, each executing instance of my session state store is, at least from my level as the applications programmer, single threaded. Then, …, REALLY should have a FIFO (first in, first out) queue for the incoming requests from the Web servers. With FIFO, at least get “fairness”, right??So, for now I’m using just the FIFO queue standard in TCP/IP — queue length of 100 might be sufficient??So, right, in a Web server, the thread communicating with the key-value store has to wait. If I really need a FIFO length of 100, that could be a lot of waiting. Hmm. So, we have a thread in some code in main memory WAITING. Generally, bummer!Sounds like a small problem in optimization on networks, some queuing math, etc.!!Ah, for the optimization math, maybe use my favorite arrival process, the Poisson process out of E. Cinlar’s book — nice chapter there!! Also, use the renewal theorem, that justifies Poisson, from W. Feller’s Volume 2.
This was the reading list last Spring:Text: Garcia-Molina, H., Ullman, J. D., and Widom, J., Database Systems: The Complete Book, 2nd Edition, Pearson/Prentice-Hall, 20091. Lamport, L., Shostak, R., and Pease, M., “The Byzantine General’s Problem”, ACM Trans. On Programming Languages, 4, 3 (Jul. 1982).2. Lamport L., “Time, Clocks, and the Ordering of Events in a Distributed System”. CACM 21, 7 (Jul. 1978).3. Lamport, L., “A New Solution of Dijkstra’s Concurrent Programming Problem”, CACM, 17, 8 (Aug. 1974).4. Ricart, G. and Agrawala A., “An Optimal Algorithm for Mutual Exclusion in Computer Networks”, Communications of the ACM (CACM) 24, 1 (Jan. 1981)5. Stonebraker, M., “SQL Databases v. NoSQL Databases”, CACM 53, 4 (Apr. 2010).6. Chang, F, et. Al., “Bigtable: A Distributed Storage System for Structured Data”, Symposium on Operating Systems Design and Implementation (OSDI), USENIX, 2006.7. Corbett, J., et. Al., “Spanner: Google’s Globally-Distributed Database”, Operating Systems Design and Implementation (OSDI), 2012.8. DeCandia, G., et. Al., “Dynamo: Amazon’s Highly Available Key-value Store”, Symposium on Operating System Principles (SOSP), ACM, 2007.9. Lakshman, A. and Prashant Malik, “Cassandra: A Decentralized Structured Storage System”, Operating Systems Review, 44, 2, 2010.10. Karger, D. et. Al., “Consistent Hashing and Random Trees: Distrubuted Caching Protocols for Relieving Hot Spots on the World Wide Web”, Proceedings of the 29th ACM Symposium on Theory of Computing, May 1997.11. Stoica, I., et. Al., “Chord: A Scalable Peer-to-Peer Lookup Service for Internet Applications”, Proceedings of ACM SIGCOMM, 2001.12. Badev, A and Chen, M., Bitcoin: Technical Background and Data Analysis, Federal Reserve Board, Washington D.C., 2014.13. Nakamoto, S., Bitcoin: A Peer-to-Peer Electronic Cash System, 2009.14. Zeng, K., et. Al., “A Distrubuted Graph Engine for Web Scale RDF Data”, Proc. of the VLDB Endowment, 6, 4, 2013.15. Malewicz, G., et. Al., “Pregel: A System for Large Scale Graph Processing”, Proc. of SIGMOD ’10, 2010.16. Graph Databases: New Opportunities for Connected Data, 2nd Ed., Robinson, I., Webber, J., and Eifrem, E., O’Reilly, 2015.17. Miller, F. W., “Operational Amortization of Algorithmic Performance in a Graph Database”, unpublished, 2017.
Ah, there’s a research paradigm!Maybe are interested in performance of some algorithm. So, want to see how it runs on random data.Okay, athttps://en.wikipedia.org/wi…https://en.wikipedia.org/wi…can find out about martingales — the conditional expectation of the future of the process given the past is the present.Amazing: Every stochastic process is a sum of a Martingale and a predictable process.Every L1 bounded martingale converges to a point — i.e., each sample path converges (with probability 1) although different sample paths are free to converge to different points.Martingales give some of the strongest inequalities in math; e.g., provide a one liner for a proof of the strong law of large numbers, otherwise not so easy to prove.Well, for an algorithm on random data, can sometimes arrange that are actually working with a martingale, use a martingale inequality, and get a relatively strong inequality for the performance of the algorithm.I learned this from a student of a member of Bourbaki.This approach has been used on some NP-complete problems.There might be some papers to be published there!I learned about martingales from a star student of E. Cinlar.My interest in research is for business, the money making kind, and to me the journals don’t pay the authors, and I don’t want to give away research that I intended to help my business make money, the green kind.
And just for fun, here’s a link to a paper I wrote last year on graph databases: http://frankwmiller.net/doc…
Thanks for all this. FYI when trying to download the pdf a warning about lots of threats associated with the file popped up.
Sorry about that. Its just a regular pdf…
“graph databases”:I’ve mostly encountered only one significant role for graphs (e.g., arcs and nodes), and that is minimum cost network flows on a graph (network) with on each arc, a maximum flow and a cost per unit of flow and conservation of flow at the nodes.As maybe you have encountered, the least cost flows can be obtained via the classic simplex algorithm of linear programming but on this network flow problem the simplex algorithm reduces to something nicely simple and has some possibly profound properties:First, a simplex algorithm basic feasible solution corresponds to just a spanning tree of arcs on the network.Second, a simplex iteration consists of adding an arc to the spanning tree, thus creating a circuit, and running flow around the circuit in the direction that reduces cost until the flow on some old, basic arc reaches zero at which time that arc is removed and the result is another spanning tree.The usual simplex algorithm sufficient conditions for optimality apply. Even if have a degenerate basic feasible solution, that is, some basic variables at 0, can avoid cycling with either R. Bland’s rule, which is from matroid theory and works for the simplex algorithm in general, or from a modification of the algorithm for “strongly feasible” basic solutions from W. Cunningham.Third, if the arc capacities are integers and we have an initial feasible solution, then the algorithm finds only integer solutions and an optimal solution that is integer — corollary, an optimal solution that is all integer does exist, maybe not so easy to prove otherwise. So, get integer linear programming for no extra effort when in general integer linear programming was one of the first known and remains one of the most important NP-complete problems. Some experience indicates that commonly when can find an optimal solution to an integer linear programming problem, actually the problem is such a network flow problem or closely related.So, for data base, have to keep track of the arcs, nodes, and spanning trees. First cut, at each iteration, have to check the circuit formed by each non-basic arc — might want to try to get some savings there.
The way to think of graph databases is that you are replacing the basic underlying data structure of the relational database (the relation) with a graph. You store data based on a graph representation which basically means you are including edge data as part of the basic structure. This yields incredible performance benefits for the real reason you want to use graphs in the first place, the rich and varied set of graph algorithms that have been developed over the course of human history. Its very powerful.Relational databases are particularly bad at graphs. You end up doing lots of joins to deal with the edge relationships and as we all know (don’t we ?), joins are the most expensive operation in rel databases and we work very hard through things like query optimization to get rid of them.
At one time I went to a lecture on performance of relational databases, and they mentioned joins. I asked something like:Okay, a join. Fine. Do the join and then do SELECT queries or whatever on the join. But, really you don’t DO the join, right? I mean, no way do you actually move all that data, say, on the hard disk? Instead, in your compiling of the query, you just pretend to do the join, and when you have to do a SELECT on the join you just thread through the given files that we imagine were joined? Right? Otherwise you might move terabytes of data to find one record that confirms that Mary has red hair!The answer was fast: Yup they actually do the joins! At the level of the software that does the work, I’m guessing it’s a lot of use of B-trees, not “binary trees” but multi-way branched balanced trees worked out way back there by Bayer & McCreight at Boeing or some such; now Google confirms my memory and adds the date, 1972 — still, that could be a LOT of disk head movement.For my startup code, for my use of SQL Server, I have an easy way to make all the joins really fast — I don’t do any joins! My use of SQL Server is quite simple; the tables are simple; no joins or foreign keys; a lot of clustered keys; a lot of GUIDs; but dirt simple. Right, each of my tables is “a function of the key, the whole key, and nothing but the key”!! So, I’m in good standing with the normal form police!Many thanks for the references!I see one by J. Ullman — I read one of his books, that starts off with EAR (entity, attribute, relationship data modeling) while eating dinner at the Mt. Kisco Diner while we were designing Resource Object Data Manager — an active store for objects to be used as essentially a cache with some benefits, e.g., locking, notifications, between a system to be managed and its managing systems. I did touch base with Mike Blasgen who confirmed his view that database needed to be more “active”.I was guessing that there would be some Byzantine generals somewhere in such a course!I see a lot from Leslie Lamport! I have some of his materials on his TLA+. Of course I first encountered his name from his work on LaTeX — I was already using TeX with Knuth’s Plain macros, and I still am, with about 100 of my macros, e.g., for cross references within the document, tables of contents, putting TeX output as annotation on an inserted figure, some simple dynamic storage allocation, etc.! I really like TeX! So, I never used LaTeX. Uh, IMHO Knuth’s original documentation is shorter and better written!I see you have a lot by Leslie Lamport.I’ll keep and index your references; then, if the time comes that I need a fault tolerant key-value store with concurrency or some such, I’ll do the reading!! I believe I remember that Microsoft’s .NET now has a collection class that supports concurrency! Maybe if they will document the internals well enough for me to evaluate it for my work, I’ll consider it. But maybe still sharding of multiple instances of a FIFO work queue and single threaded code will be fine! TCP/IP programming is a lot of fun. I did recently read that Microsoft supports program to program communications within an AppDomain (get more performance by having several applications in one address space but maintain security?), a process, and among several machines; I’m guessing I’d rather just keep using TCP/IP!Thanks.
Many of the references are fundamental results. “Physics problems” in the CS world in some sense. The Byzantine paper is one such paper and is focused on such a core problem (distributed decision making) that it manifests itself in almost everything else. Its also the fundamental result that causes convergence to be slow in cryptocurrencies. Fred whines about this and so does everybody else, but as I said, its a “physics” problem.I listened to the video clip that Fred put up last week on the lecture from the MIT guy. Very good talk although at a laymen’s level and very sales pitchy. He made some claims about Byzantine agreement that raised my eyebrows. I need to go look at his results. For example, he makes claims that you can subset the nodes involved in the decision based on randomness and skip the Byzantine 3m+1 result based on probability. While this seems intuitively ok, there are some bad pathologic cases that destroy the result. Not sure I’d hang my hat on it.The other paper I would focus you on is the Consistent Hashing paper. This is a fundamental structure that underlies many of the fully distributed systems that have been built in the last 10 years, Cassandra being a good example.Typically data is kept unordered in the actual relation so its just a sequence of tuples, order related to when they were inserted mostly. Indexes are built to get around the having to iterate through the relation everytime you want something problem. The indexes typically use something like a B+-tree or a hash table on secondary storage. Their purpose is to speed up search at the cost of keeping the index data structure.
Thanks!Yes, of course I’ve heard of the Byzantine generals problem for decades and likely have seen references to the same paper. I always regarded the problem as possibly interesting for situations of concurrency and/or distributed systems and otherwise only a puzzle — and since I wasn’t much interested in puzzles and didn’t have pressing practical problems in distributed systems or concurrency, I didn’t pay much attention.Thanks for emphasizing the fundamental nature of the problem, the physics aspect. So, maybe now we have that first, long coveted result in computer science, a non-trivial result beyond, say, heap sort, the Gleason bound, AVL trees, and B&M B-trees (likely much the same as B+ trees?) :-)!!!. Also how to back up a relational database while it is busy reading and writing — easier to do than it sounds, not really as important as e = mc^2. Microsoft’s VSS (volume shadow copy) for backing up even a running booted hard disk partition while it is running is now old stuff and apparently much the same idea and, I suspect, a standard part of .NET. I have a friend who once coded up B-trees — he said it was tricky to get it all correct!Thanks for the role of B+ trees in relational data base keyed tables. In my startup, I’m asking for “clustered keys” which are supposed to give essentially sequential reading of the table rows in the same order as sequential on the keys. In production, those tables are essentially read only which, of course, gives some easy ways to get quite high performance from sharding. Sure, building a 1 TB table with clustered keys might take some effort, but likely won’t do that more often than once a week. Then “do a switch over and hope we don’t get a burnout”!! :-)!!I know; I know; solid state drives change this situation and will be especially attractive for high performance read-only (read often, write rarely) — I should be into $50 million a year in revenue before I need to exploit that!By then the table will be 10 TB and in some non-volatile solid state storage nearly as fast as DRAM but that software can access as DRAM, the whole 10-100 TB!! Keep that busy and looking at $1+ billion a year in revenue.Right, the challenge is getting enough users to keep it busy!!! :-)!!Hmm, with GUID keys, maybe we should consider some uses of radix sorting???!!!!On hashing, our project at IBM once made use ofRonald Fagin, Jurg Nievergelt, Nicholas Pippenger, H. Raymond Strong, Extendible hashing — a fast access method for dynamic files, “ACM Transactions on Database Systems”, ISSN 0362-5915, Volume 4, Issue 3, September 1979, Pages: 315 – 344.”Look, Ma, easy way to keep it fast and have no collisions!!!”, i.e., hashing anyone can trust! I’ll have to compare with the hashing paper you mentioned.Since both hashing and Byzantine generals involve evaluating performance on random inputs, there’s an outside chance that my hint about getting strong inequalities from the martingale inequalities could work. Not a lot of people with a foot in both such computer science and all the sigma algebra manipulations in martingales.Of course the machine learning people really like Leo Breiman, especially for his work on classification and regression trees, etc. And one of Breiman’s books has an especially nice chapter on martingales, e.g., with all the sigma algebra details just correct. But of course, that book with the chapter on martingales by Breiman is not the one the machine learning people like!! :-)!!.I really wanted to do theoretical physics.Sometimes I still wonder — if an electron goes through a beam splitter and we wait a million years, say, for a VC to want to fund my startup!, and then another 2 million for me to be willing to take their check!, then the quantum mechanical wave function of that electron is in two pieces very widely separated. We could put a detector in front of both paths and be sure we would get at most one detection, not two. Okay, but that electron has mass and kinetic energy, thus, has to feel gravity and generate gravity — not a lot but necessarily some. Okay. But for the two parts of the wave function, where is the gravity, with one, the other, or both? Probabilistically, or as a physicist would say, statistically, equally on both, but to heck with such law of large number averages and consider just that one electron — where’s the gravity? And if the electron is detected from one part of its wave function, then what the heck happens to the other part millions of miles away — what happens to its mass, kinetic energy, gravity, and WHEN????? The two parts of the wave function can’t just be ignored because we could have some mirrors that bring them back together again and interfere as in the Michelson–Morley experiment. And, sure, whatever happens with the two parts of the wave function after a detection, what about if one part of the wave function goes into a black hole — will that change what can happen to the other part? Ah, silly stuff. I gave up on physics because the math was so sloppy.So, I concentrated on math, eventually relatively applicable math.For computing, my main interest is having it do the manipulations for the math, in particular now for my startup.For that startup, so far the computing looks dirt simple — no challenges at all. It was 5000+ Web pages on .NET, some struggles with system administration for SQL Server, and 100,000 lines of typing, but otherwise just fast, fun, and easy — no problems at all. Getting the glass back into the driver’s side door of my Chevy Blazer SUV last night was harder!!Oh, right, at one point in my code, I want to do a binary search. Okay, suppose I have a sorted array of 10 million components and want to do a binary search — piece of cake, high school freshman exercise. Programmed it myself off and on several times. All so easy that part of Knuth don’t even have to read at all.But suppose we have 200 keys to look up in that array of 10 million. Sure, just call the binary search routine 200 times. Hmm …. Anyone just looking up words in a dictionary or stacking books in a library would be smarter than that! So, just sort the 200. Then when have done a lookup, the next lookup has fewer than the 10 million to search …. Okay, there are several such approaches. What are the best, when, and how much better are they? Sure, I coded up something, a first guess — I call it “block binary search”; it appears to run and is in my code, apparently ready for production. Maybe I’m only person 10 million to think of this, or maybe not. Maybe it’s an exercise somewhere in Knuth, Sedgwick, Ullman, or Lamport — maybe not! Maybe it’s a patent (but as of now it’s already “prior art”!). Maybe use the martingale stuff to get some inequalities for random data, which would be the first cut evaluation.But I don’t want to rush to try to get a peer-reviewed publication of such; instead I want to get my startup well into the tall, green stuff, MONEY.Thanks for the overview! I’ll keep it!
Thanks for sharing this