Hacker News and the NoSQL Movement
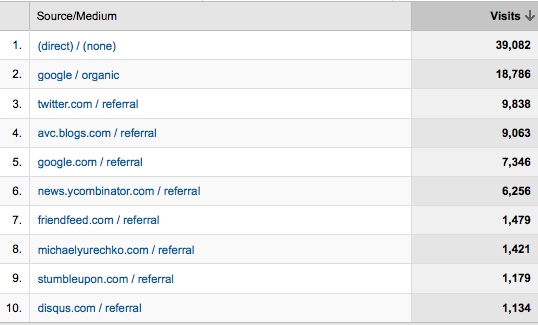
I love Hacker News (aka news.ycombinator.com). I read it at least once a day and it sends this blog more traffic than anything other than Google and Twitter. This is the refer log for AVC for the past month.
But like every great web service out there, it's the community at Hacker News that makes it so great.
This morning I read a Computer World article about the "NoSQL" movement. It was interesting to me because we have an investment in this market sector, an open source cloud based document store called MongoDB (which is mentioned in the computer world story).
There are three comments at Computerworld.com and there's 43 comments on the story at Hacker News. If you are interested in database issues, you'll find the discussion at Hacker News interesting and informative.
The SQL vs NoSQL debate is important, serious, and deeply technical. I am not going to even attempt to weigh in on it (other than to say we've got an investment in a NoSQL data store). But plenty of people are weighing in on it at Hacker News right now.
Of course there are other tech communities out there where discussions like this one have been going on for years. I am not saying they aren't vibrant and important. But Hacker News brings that together with a "techmeme style" blog aggregator and focuses very much on the startup entrepreneur (which is why it drives so much traffic to this blog).
Hacker News is a great service. If you are involved in tech startups and you don't read it regularly, you should.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=aba30a17-4596-480b-85de-af6b34a83e37)
Comments (Archived):
Fred – no question about it. Hacker News is a must-read for every entrepreneur or even anyone thinking about dipping in. I’m a fanatic evangelist of the site here in Europe, where I think it’s still not as big as in the US.One small point worth mentioning is the value of the “ASK HN” posts – this is something no other news community offers. Entrepreneurs & hackers (even VCs) often post questions about anything related to technology or startups, and the quality of responses is amazing. People take a lot of time to write helpful and very well thought out responses in a genuine show of support. It still amazes me every time – we’ve used ASK HN posts for advice related to MySQL issues, sales, UI feedback and even where to stay in a new place!Thanks for highlighting such an incredible resource.
thanks for highlighting the ASK HN posts. I’ve never used them but they sound terrific. i wish paul would buy hackernews.com. that’s my only beef.
Figuring out the correct URL for Hacker News is the minimum entry requirement to be able to join the community. If you can’t do that, then…
well that’s not too hard.i think all important services on the net should have their own domainsit’s just a pet peeve of mine
I once had a really interesting conversation with a rabbi friend about minimums to join a community. The context was a fairly controversial one in the Jewish community:conversion and the requirements for conversion across denominational lines, and within denationalization lines, and its relationship to intermarriage. He was also pursuing a Masters that peripherally involving the subject, at the time. We came to the following conclusion:Making the barrier of entry lower can make less vested people involved, but only peripherally. However, it also means information more freely spreads and that that information can mutate very quickly to provide newer and even more sources of information. We also came, somewhat, to the conclusion that it is not as much as a true barrier as one that is similar to that of membrane- permeable. I still take the position that much like a real cell membrane- it is permeable both ways.As one can see from the data above about Fred’s website- many people stop by. Not so many log comments. There is a barrier of entry here, I admit to some days being fire-hosed and running around trying to figure out what is going on. (I stay to be educated)How do you think sites HackerNews and even this one should be constructed to help people who want to pass through the barrier in both directions? It is not just a domain issue, it is a much larger issue of usability, knowledge, and how to make information available in progressive steps with reinforcements for progress along the way, alongside the flip of how to make comfortable social spheres to help those through the transition processes.Not that certain knowledge should be Elite- but how to make the eliteness more structured in a friendly way?The Internet sometimes feels like it disguises the social issues it creates- too much of a firehose of knowledge some days, not enough on others.
We need digests of the comments. I call it ‘comment cliff notes’. Someone’s gonna do it and it will suck a lot more people in than the current approach
That spreads knowledge- and mutates it.How does it provide structure and engagement? The flip is not necessarily a bad system either. In any knowledge creation and curatorial system- one still needs a system in which to engage in and delve deep just as much as one that propagates the knowledge that is out there in new forms?You once said you were trained like an apprentice. The question for me, is not how to suck people in- but rather how to give people better apprenticeship experiences through a wider system of gaining those contacts and knowledge bases, without sacrificing the tail end of extremely good knowledge and expertise that sometimes only happens when individuals and groups break off away from the mass.
The real value in Hacker News for Paul and YC is to get people interested in startups and aware of YC funding. Keeping it tied to the ycombinator.com domain is a big part of that.
I wish more news sites would use their format.newmogul.com looked interesting but has failed to build the same type of community.
i like newmogul as well and visit it dailythey’ve got the right aggregation model and UI (I agree about HN’s UI), butnot the communityHN has the benefit of the YC community as its seednewmogul needs something like that
Hacker News is written in Arc and is open source. New Mogul isn’t just the same format as Hacker News, but the same code.http://arclanguage.org/install
Cool, did not know. Going to play with it.
This article seems a little weird to me. It seems like what they are calling a no-sql movement needs clear distinction. Hadoop and mapreduce are large storage methods that don’t really have quick random access. MongoDB is more of an efficient random access database and when I last asked them they didn’t support multi-core Hadoop HDFS which is what you need to store tons of data (yahoo, google, facebook, aol’s problems) and if you are a site that’s growing a massive data set you still have to shard your database. That said if you are using Hadoop you still need to roll data up into mysql in order to randomly and quickly access it.I’m not saying the article is missing the shortcomings of these different technologies but they are definitely blending them all together as if they are all the same thing and equal competitors when they are in fact not.That said I work on the business side and don’t intimately use these technologies….just sell the benefits of the data and info they provide so if anyone understands this space better I would love to hear your opinion or you correct me or set me straight on this stuff. (which i was hoping that article would do and it did not)
I’ve always loved that Y Combinator is “eating its own dog food” in terms of using one of its startups’ products, the Reddit engine, for Hacker News.
It’s not. Hacker News is written in arc and distinct from Reddit.
Really?! Cheers for the clarification – I’ve been misinformed ;-)They’re so similar as well!
There’s a lot to like about YC. They’ve created a whole new class of venture capital it seems
Regarding the NoSQL thing, I believe (for now at least) there’s something to be said for ‘horses for courses’. I deal with legacy systems on the backend of my application, so I must work with SQL (and for the extremely complex system involved, I believe that makes sense). However, when it comes to things like page or fragment caching, NoSQL is a great idea.
i think it would be great to create a wiki (maybe one exists) for applications where NoSQL makes more sense than mysql
Agree with this. Alternatives for the relational database are emerging due to1) Architecture incompatibilities the make RDBMS a difficult fit2) Problems with the RDBMS (scalability, consistency) that prevent it being used even when it is a suitable fitSolutions include building data architectures based loosely around DHT’s (MongoDB, Project Voldemort, Cassandra, Redis, Wistla etc) or other distributed architectures (Hive & Hadoop more generally etc), fixing some of the RBDMS’s problems (GroovyCorp, Vertica, Drizzle etc) or marrying the RDBMS with other technologies (Aster Data with Map/Reduce etc)When the dust settles there will be the need for all.
It would be great for someome (maybe everyone via a wiki) to start cataloging these different data store technologies and what each is good for and bad for
There is a wiki here http://www.bigdatabaselist.com although it doesn’t go into the good & bad use cases, but I like that idea and will encourage it.
Awesome. I’ll check it out
Nice summary – another candidate for leveraging existing RDBMS’s is through the use of in-memory data grids. I touch on this in my post about the NoSQL movement in the context of legacy systems:http://bigdatamatters.com/b…
I didn’t realize MongoDB was part of your portfolio. When my post on Tokyo Tyrant made it on to HN, Geir Magnusson reached out in the comments. That got me looking seriously at Mongo, as did the comments praising the team’s customer service, they deserve big props for that.It’s great to see the NoSQL movement getting mainstream recognition too. I took my own stab at why startups are moving to key/value stores in The SQL Trap:http://petewarden.typepad.c…
Pete: I love the notion of the SQL trap. I’ve seen so many of our companies get caught in it. Thanks for sending me that post. I loved it
Big fan of HN the detailed comments make visits there a knowledge payoff. I strive to make my own blogging HN worthy- admittedly I wax a little more philosophical than their standard fare.Paul Grahams essay’s and ycombinators framework were influencers on my view about the feasibility of a low cost business and potential open development areas
I’m working on a book for Apress about Amazon SimpleDB (another database in the cloud)…we talk as much as we can about when something like SimpleDB makes sense vs. using a traditional relational database…But I think you need to be careful about calling it ‘NoSQL’…SQL is just the language used to talk to a traditional relational database (structured query language)…and many of the new systems, like SimpleDB, that are completely different concepts on the storage side still offer up a SQL syntax for inserting data and getting data back out…So anyway, I think it’s more about ‘NoRelational’ than it is ‘NoSQL’…
good pointi didn’t make up the term, i just used it, which i guess is implicity sayingi like it
The problem with distributed key-value (“NoSQL”) stores as a replacement for relational databases is that the NoSQL engines are *miserable* for most types of fast and deep analytics. Traditional B-tree-based relational databases do not scale, and distributed hash tables don’t do complex data models and analytics. It is a tradeoff, and an unfortunate one at that since data sets are growing rapidly and applications are increasingly focused on fast, contextual analysis of that data. NoSQL is not a replacement for relational databases, it is just considered an acceptable tradeoff for some subset of applications. I do not think many people appreciate just how limiting the NoSQL engines really are.This tradeoff is rooted in a set of unsolved problems in computer science; if you solve the core problems, you get the best of both worlds and both the traditional RDBMS and NoSQL platforms become obsolete. Very few people in this space, even technical people, seem to fully understand the underlying theoretical context in which database technologies are embedded. If one of the core problems was solved, it would look sufficiently different from existing SQL/NoSQL art and be sufficiently technical that I doubt most VCs would give it much of a look despite the revolutionary potential. (Indeed, the couple recent startup ventures I am aware of that have made significant progress toward solving the core algorithm problems are largely ignored by VCs, and have been raising their money from defense agencies and customers with the acumen to recognize the meaning of the algorithm advancements.)NoSQL is a technical stopgap until the real computer science and algorithm problems are addressed, and there is a lot of progress being made on that. As an investor, it seems wiser to invest money in the ventures that will obviate the use case for NoSQL (and traditional RDBMS) rather than investing in the stopgap measure. There are systems being worked on and tested that are capable of doing complex analytics even a traditional SQL database can’t do well, but at scales and with throughput traditionally reserved for systems like Hadoop. From reading the coverage of such things, I expect a lot of people to be caught off-guard when products are released that do not fit into the SQL/NoSQL false dichotomy.
James, you make some very valid points.KV stores are not really databases at all, they’re really just like the indexes used in a traditional RDBMS (except, of course, they are writable). They make sense when you just need a simple and fast way of getting info in and out of a web page. As you rightly point out, if you want to slice and dice the contents of a KV store in new ways, then you basically have to do all the processing yourself.There is definitely scope for the creation of a system combining the speed and simplicity of a KV store with the flexibility and power if an RDBMS.For what it’s worth, we use both systems: we use a KV as the front-end and mirror the contents into an RDBMS in the background. It’s not perfect, but as long as all the writes go through to KV, it works OK.
Using hybrid systems that puts most of the update/write load into a KV store and reserving the RDBMS for complex constraints and long-term persistence is essentially current best practice. It uses the KV store as a fancy write-back cache, and for most current web apps this works very well.I think the nascent focus on “real-time” is going to be the straw that breaks the camel’s back because it requires highly scalable updates over complex constraints, meaning that you cannot hybridize your software stack. Worse, constraints are a spatial data type, which have always performed poorly in conventional RDBMS when treated as such. Databases that focus on real-time search have been around for decades from the major vendors under a few different names (stream databases, adaptive dataflow engines, etc), but the reason no one has heard of them is that they scale and perform badly outside of very limited domains.The best-of-both-worlds solution is simple (in a geek-ish sense) to describe: We need a database built on a parallelizable, associative space-preserving hyper-cube access method. Only a handful of database theory people are familiar with this, and only a few academics have even heard of the only access method algorithm in literature that comes close to delivering it. Nonetheless, there are a few people working on it because the potential is mind-boggling. Real-time search, complex data fusion (think Photosynth on Internet scales), deep predictive modeling, large-scale geospatial, and sensor-based contextual targeting are all applications that depend on a solution to this problem to scale well. It would make for a frankly amazing database system.(Disclosure: this is my area of expertise, I have on worked on this problem space for Big Companies and occasionally do technology evaluations of database startups for VCs.)
Wow. You lost me at hyper-cube, but it all sounds very clever.
Don’t worry I had to look up hypercube in wikipedia.Do you remember A Wrinkle in Time? A tesseract is a hypercube of the space we are in now.Not that I understand the math (I wish there were more teaching methods of math that were both proof/theory oriented and visually oriented at the same time.), but it sounds like you are saying you want to “fold” through the data by giving it another spacial line to expand and rotate on.I’ve only played with SQL (which in its most basic form can be a Relational database system with a few minor constraints on it): It seems to exists only as interconnecting two dimensional spaces. To really have deep data as well as broad data, you would need to have three or four axes to rotate around and stack on for some sort of “keying” system, because otherwise how will you cut through the stuff you don’t want.It’s like having a really big spaceship above earth that is really fast, doesn’t obey Physics, and you can put it down on Earth where-ever you want. That is what you are looking for in this new kind of database? (Or at least this is my image of it…)
Thanks for trying Shana, but if I’m honest you’re just making things worse…When I was a nipper we just stuffed n-dimensional data into an n-dimensional array, but that was when computer screens came in any color as long as it was green.But I loved the ‘really fast big spaceship’ analogy (whatever it means)+1
I was hoping you would say- when computer programs were still on cards (actually does anyone know where to get those cards?)Have you ever read Flatland by Edwin Abbott? I’m thinking I and my data live in Flatland with and I need some spaceships from an intruder from the next dimension to get to my data. (If not- http://xahlee.org/flatland/…A spaceship that can go “through” the earth? Because Flatland only ends in the third dimension- whereas the spaceship can deal with other since it is in a mysterious “above” plane.(and I was hoping you would say you programmed on those cards, I really could use some of those cards…)
Steady, dude-ess, there’s a difference between old and ancient!And whilst I am curious to know how you managed to connect databases and spaceships, what I would really like is for you to pass the bong over…As for the cards, all I can suggest is eBay (they’re quite boring, when you seen one you’ve seen em all).Take care now.
Never smoked a hookah in my life- I’m quite the innocent.I’m an art student- it’s for a sculpture made up of various kinds of computer data storage materials throughout the “ages.” My language in the end is very visual.
It is simpler than it sounds, a hypercube is just a cube in a logical space of arbitrary dimensionality i.e. a rectangle is a “cube” in 2-dimensional space.Consider an “employee” table with three attributes “name”, “title”, “employment date”. The three attributes are ‘dimensions’, and every record in the “employee” table can be located in the space of all possible employee records using those three attributes as coordinates. In this way, the employee table describes a 3-dimensional logical space in which all possible records will exist. A query on the employee table is searching for a region of that 3-dimensional space that contains the coordinates described in the WHERE clause of your SQL.The complication is that in traditional databases we would use a collection of 1-dimensional indexes that are merged to simulate a true 3-dimensional index, and that merge operation does not scale. This problem becomes much worse if you have true spatial data types, like geospatial or constraints (such as what one might use for real-time search).Ideally, you want a data structure that can directly represent several dimensions such that any subset of the space those dimensions describe can be very efficiently accessed in a distributed system *and* the data structure can efficiently store data types that can be described as a subset of that space. It is a very tricky problem that has generated thousands of pages of research over decades. We’ve been using workarounds for years but the rapid growth of data sets has exposed the lack of scalability intrinsic to those workarounds, forcing us to deal with the underlying problem directly.
I see that issue in my head better than I can describe it- I could draw it.The issue for me with a hypercube, especially once I looked it up- is its shape and its ability to rotate. If you solve the issue of what shape (because there are many possible n) and how you want to rotate it (there are more axes with each n added) (and those rotations reveal all of the potential shortest distances within the hypercube, or your where statements) then you resolve the problem.Being “above” the shape, or having the ability to re-look at the shape from a totally different perspective is what is giving me trouble.Ideally, the more dimensions you have, the more possible hypecubes, and imagining yourself from above the dimension(s) allows you to “play” with each block more efficiently in your head to find out shape one needs in order to really get the shortest distance from point a to point b if one can only take the lines within the hypercube of any n dimensions.Hence the need for a really large and fast spaceship. You need to be “above n hypercube,” and then think about what happens when you add a new n about how it looks and behaves. Spaceships move and are above the earth and if the earth was my hypercube- I could see and use my spaceship to figure out where to go one I got back down onto it by looking around it.Unless this is more lost than before? I understand the idea of cube trying to stick itself into arbitrary space as we define it- it’s more where do I look at the cube that I am trying to understand, or how should I look at the cube to see as much of it as possible.
The scalable structure you describe sounds interesting, I’d love pointers to literature you think is interesting on the topic (I’m familiar with linearizing onto hilbert curves or the like). You’re likely already familiar, but just in case, you may find some of the work descending from SDDS’s like LH interesting. I can’t recall the specific paper, but there was one that descended from CAN that handles partitioning a hypercube amongst peers and the routing necessary on such a network to execute queries.But, I also think it the focus on SQL or index structures actually misses the point slightly in the context of data storage for large web applications.The big problem is the generals.It’s not just about moving away from SQL, it’s about being forced to deal with the reality that maintaining one consistent view of data stored on multiple nodes has unacceptable performance penalties. Inktomi was the first to run into this in the setting of internet services and all large internet properties are treading onward from the same trailhead they established.Consensus protocols have unacceptable overhead, so in practice they’re generally only used for maintaining critical lookup values for some larger system that leverages weaker consistency requirements.Scalable partial query result merging doesn’t matter for real systems because Read All Write One or Read One Write All end up working better.For example, let’s look at Google’s inverse word index for search queries. It’s too large to fit in one host, so we must partition the state in one way or another. At first glance the best way would probably seem to allocate the inverse lists for specific words to specific hosts, via hash, directory or some other method. This way a given search only needs to query the specific servers that hold inverse word lists for terms in the search.This isn’t how google actually does it.Instead they partition by document, and a given search is broadcast to all servers. At first this seems quite wasteful, but it’s actually a better fit to current hardware constraints. Each server can apply the full query against each document, avoiding the intermediate merge problem entirely and only returning full matches.This works better because bisection bandwidth is the least scalable resource in large systems.This system is straightforward to scale as well. Need to store more documents? Add nodes. No need to worry about a single inverse word list growing beyond a single host and requiring more complicated behavior. Need to process more searches? Replicate the entire cluster as many times as necessary, and accept that replicas will never be exactly in sync. As long as your load balancing sends users preferentially to the same replica you’ll avoid making replication lag visible for most users.Scaling and operating RAWO systems like this is simple. I’d love to see a SQL database that used the same architecture: INSERTS to random nodes, all other statements broadcast, and each replica cluster does async or partially async multi-master replication.ROWA systems don’t scale, but for systems that can live within those limits they’re a far simpler method of high availability (example: atomic broadcast like zookeeper vs implementing paxos).And of course there are many interesting approximate quorum systems that live in the region between those extremes (such as amazon S3, which I gather is R2 W4).
Damn you guys are smart!!!!!! I feel very fortunate to have people like you commenting here. Thank you
jason, can i email you? i want to run something by you.
Not sure how much help I’d be, but sure. My email is [email protected] (pdx isn’t part of my last name).
James,It is clear that this is your area of expertise, so I had to think twice (well, in fact it was even more than that) before replying to your comments.It is my understanding that your comment implies that there is a solution that would address problems of both worlds: relational and KV. I’m not an expert in the field, but my perception is that if this solution would exists it will be once again something that will try to fit every problem. And this is exactly what happened with RDBMS (what is now called the one size fits all RDBMS).While I cannot formulate a general rule and I’m basing this hypothesis only on my experience, I’d say that special problems will always need a special solution. Not to mention that I still don’t believe in the existence of a panacea. Starting to trust again in a single approach will just limit the solution space we are looking into.I think that what we should be looking for is a way to address the impedance mismatch between RDBMS and KV and make the two cooperate in a much easier and standardized way, to address the impedance mismatch between current programming paradigms and storage by aligning the access layer and figuring out the ‘interaction language’, etc.A radical new paradigm is definitely welcome, but I think that will take a long time to be proved theoretically and even more to be proved by real live apps.cheers.ps: I’d love to learn more from you about this new approach, so I’m wondering if it would be possible to move this offline somehow.
Same here
james, can you point us in the direction of the startups that have made progress solving the core algorithm problems? I agree that it is unlikely that a VC like me would give such a thing a “good look” on my own. but one of the reasons I maintain this blog is that the community here can see things like this that i can’t see and show me the way.thanks for a great commentfred
Fred, there are a number of companies nibbling around the edges of the computer science problem, notably some geospatial analysis ventures, but their focus is on specific applications rather than the more general database problem. Some big companies are also doing related work, but not much of interest.The startup to watch for next-generation database technology that addresses the issues being raised here is SpaceCurve. Their database platform is based on some very novel computer science that implements something like the exotic best-of-both-worlds access method I mention up-thread. Virtually all “new” database startups are rehashing existing computer science but that one stands out as both doing something completely different and demonstrably attacking the limitations of current technology.As a general comment, there is a pattern I have seen before with startups that have technology based on fundamentally new theoretical computer science is very hard to sell to VCs regardless of the capability. The only people that understand what those ventures are doing are other organizations that have already invested considerable R&D in solving those same theoretical problems, which in many cases become “customers”. Because there is little real technical expertise outside of that pool to evaluate the technology, most VCs do not want (or can’t afford) to invest the time to develop technical expertise. There may be a demonstrable market, but not understanding what that market is really about is a major hurdle because the long-term upside is hard to gauge on that basis. I understand why this happens, but a lot of money gets left on the table and a lot of technologies are under-exploited as a result.
Thanks james. I’d like to get to know you at some point. Let me know if I can contact you about that
Fred, it would be my pleasure. Contact away.
How would you compare HN with Reddit? To me the two communities seem pretty similar (or at least the tech communities).Anyways, what I’d be even more interested to hear (probably in a separate post) is about your involvement in MongoDB project (rationale, future plans, etc.). I’ve been following this market for quite a while and so far my impression is that most of these projects were created to solve very particular problems (I use as a proof the fact that until recently these guys have never talked to each other and instead of working together in the spirit of open source community each have jumped to implement its own).thanks in advance
i’ve never been taken with the reddit community. i agree the services are similar and i know reddit is a great service, but for some reason, i visit HN and techmeme, but not reddit and digg.what more would you like to know about MongoDB?
re: HN, TechMeme, Reddit, Digg: might it be the signal-to-noise ratio that made you like more HN and Techmeme? (I confess I have a supposition about these sites and their target audience and I’m just trying to validate it)re: MongoDBWhile I’m familiar with MongoDB, I don’t know much about MongoDB plans, so I’ll just speculate here — in my extremely obvious attempt 🙂 — to make you say more about what convinced you to invest in MongoDB (and leaving aside the team argument). Do you think MongoDB will possibly become a MySQL equivalent (not saying replacement or alternative though) and start using the same model? Or is it that you see opportunity in the open source backed services (f.e. cloudera, springsource, etc)?
Well mongo came out of an attempt to build an entire open source stack in the cloud that we backed (10gen). That turned out to be way to ambitious and as we were getting ready to call it quits, we saw some interesting activity around mongo. So we re-oriented the company around mongo and now its starting to gain adoptionSo like most things we invest in, the opportunity changed post investment
Quite interesting! I must confess that even if I knew about 10gen and MongoDB I haven’t put the story together, so now everything makes sense.Thanks a ton
“… Hacker News is a great service. If you are involved in tech startups and you don’t read it regularly …”But not if you want to get something done. Sometimes it gets a bit too addictive so I just watch the tweets & very occasionally read the articles & maybe the comments.
True. I’ve learned to skim/speed read
You are right about hacker news. All serious hackers should scan it daily. And using ‘Ask HN’ on a highly technical algorithmic question got me far better answers than Stack Overflow.I too have been dabbling with key-value stores, but I am still troubled by a comment I read a while ago on Hacker News (http://news.ycombinator.com…’In every business I’ve ever been involved with, the data is always more valuable than the code, and it always outlives the code. Too much of the hype around these alternative database technologies are throwing the baby out with the bathwater. The idea that “most” applications don’t need structured data just strikes me as incredibly naive and short-sighted. Far more applications need structured data than need to scale.’
Thanks Fred for sharing this. Its refreshing to find a clean aggregator with amazing content. One look at it and I am already hooked
First, I am NOT arguing for/against any technology here…just some comments based on my experience.It was OODBMS vs RDBMS in 90’s and this following CNET article says it all-http://news.cnet.com/Jasmin…(This article dated Dec’97 says time has come. That time never came for Jasmine!)Now it’s key-value vs RDBMS and I think RDBMS will again.I agree with the comment by a key-value developer:”A few specialized applications can and have been built on a plain DHT, but most applications built on DHTs have ended up having to customize the DHT’s internals to achieve their functional or performance goals.”http://spyced.blogspot.com/…Then the computer world article is wrong. FB uses how many thousands of MySQL? Why FB hired a MySQL expert recently? Are they going to throw out all the MySQL instances in the near future? no way…Why Facebook/Yahoo is building SQL on top of Hadoop? Why Cassandra alias is discussing SQL like for Cassendra?Even I myself said, Good bye SQL: (i may be also wrong; it might have come out from my past OODBMS experience)http://uds-web.blogspot.com…So, the question is NOT about SQL vs NoSQL and is about what type of database technologies needed for the next gen web apps?
Agreed. That is the consistent message coming out of this excellent comment threadThanks!!
Another factor in this space is people issues and this is nothing to do with technology.If a DBA runs Oracle/SQL Server/DB2 and looses data, he is OK.If a DBA runs any of these un-proven DB and looses data, he will be FIRED.So it catch-22 for any new DB’s. They need big customers to prove that they can scale and sustain the load and customers wants to see the real time deployment before the adapt it!
So true. But the hacker who builds the next facebook on hadoop can’t get fired because he works for himself
I totally agree. But the same hacker once he grows his business, guess where he will lookup for the storage solutions? It’s Oracle & NetApp’s of the world.Here is a classic example: Facebook using Oracle: (note the date- April 09)http://www.oracle.com/custo…
Facebook is a poor example for several reasons:- their needs are only typical of a handful of the largest web properties- their use of mysql is heavily sharded, which means throwing out most of what SQL gives you- most of their actual data access is done to memcachedThis architecture resembles a key value store much more than it resembles a traditional RDBMS installation. They’re essentially using MySQL as a recovery log, memcached as their hot data store, and implement query processing in the application.
Are you talking about MongoDB? I am trying it today, because I need a proper document database, instead of a simple key-value store.
yes, we are investors in 10gen, the company that has built the MongoDB opensource datastore